网络系统实践:协议、命令、系统、编程、优化、应用
1. 应用层协议与通信补充
实时通信:WebSocket、WebRTC、MQTT、XMPP。
数据传输:HTTP/2、HTTP/3、FTP、SFTP。
安全通信:SSL/TLS、IPsec、SSH、WireGuard。
其他协议:gRPC、CoAP、AMQP、STOMP。
新兴技术:QUIC、RSocket、GraphQL over WebSocket。
1.1 HTTPS
明人不说暗话,HTTPS 主要做三件事:
数据加密:HTTP传输的数据是明文的,容易被中间人窃听或篡改。HTTPS通过使用SSL/TLS协议,对数据进行加密,确保数据在传输过程中无法被窃听,保护用户隐私和敏感信息的安全。
身份验证:在HTTP中,服务器无法验证客户端的身份,也就是无法确定用户是否与他们通信的网站真实的服务器进行通信。HTTPS通过数字证书,确保客户端正在与合法的服务器通信,减少了中间人攻击的风险。
数据完整性:HTTP通信不提供数据完整性保护。攻击者可以在传输过程中篡改数据,导致内容损坏或潜在的安全漏洞。HTTPS通过使用加密哈希算法,确保数据在传输过程中没有被篡改,保持数据的完整性。
我们就从这三个方面出发。不过在这之前,我们需要了解一些密码学。
1.1.1 简单密码学
下图中 Alice 要发报文给 Bob,双方用各自的密钥进行解密和加密;Trudy 是入侵者,假设他可以获取密文。
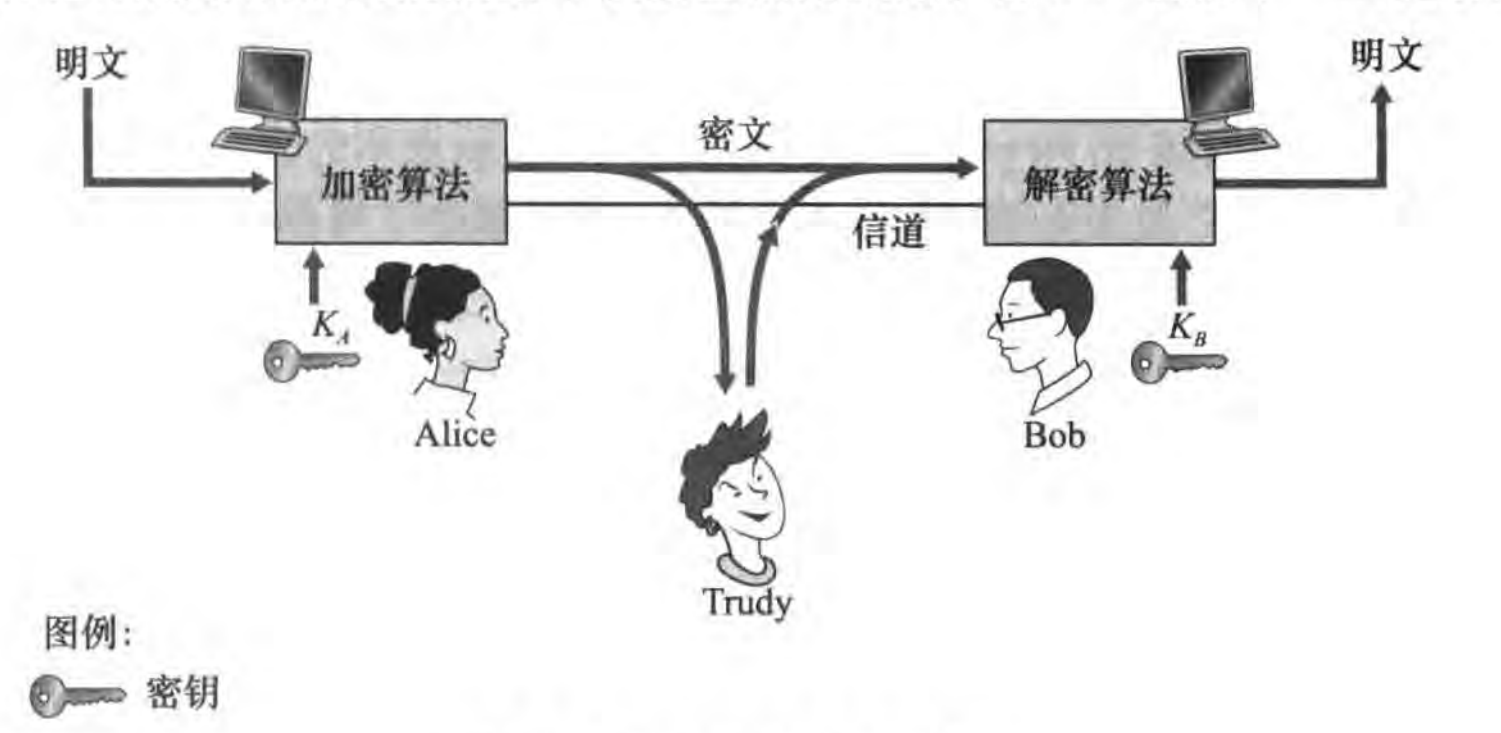
有两种密码学系统:
对称密钥系统:Alice、Bob 的密钥相同且秘密。(Alice、Bob知道,Trudy不知道)。如AES算法。
公开密钥系统(公钥系统):使用一对密钥。一个密钥两人以及全世界(Trudy)所知,另一个密钥只有 Alice or Bob 一方知道,而不是双方都知道。如RSA算法。
对称加密:AES
AES 加密过程包括多个步骤,主要分为 加密 和 解密 两部分。以下是 AES-128 的简要流程:
加密过程:
密钥扩展:
把初始的密钥生成一组“轮密钥”,每一轮加密都会用到这些密钥。初始轮:
用第一个轮密钥和明文数据进行一次简单的混合(异或操作)。主轮(重复 10 次):
每轮都会进行以下四步:替换字节:用一个叫 S 盒的工具,把数据里的每个字节替换成其他的字节,起到打乱的作用。
行移位:对数据的每一行进行循环移位,调整数据的排列顺序。
列混合:对每一列的数据做一些数学运算,进一步增强混淆效果。
轮密钥混合:用当前的轮密钥和数据再次混合(异或)。
最终轮:
和主轮类似,只不过省略了“列混合”这一步。
解密过程:
初始轮:
用最后一个轮密钥进行一次混合(异或操作)。主轮(重复 10 次,逆过程):
每轮会按相反的顺序还原数据:逆行移位:把行移位的操作反过来,还原数据的排列顺序。
逆字节替换:用 S 盒的逆操作,恢复原始字节。
轮密钥混合:和加密一样,用对应的轮密钥进行混合(异或)。
逆列混合:把之前的列混合操作逆转回来。
最终轮:
和主轮一样,只是省略了“逆列混合”这一步。
除了 AES 之外还有 ChaCha20.
非对称加密:RSA
Bob 生成了一对公钥和私钥,将公钥 (e, n) 公开,私钥 (d, n) 自己保存。
Alice 用 Bob 的公钥对消息加密,并把密文发给 Bob。
Bob 收到密文后,用自己的私钥解密,获得原始消息。
RSA 的安全性基于质因数分解的难度,随着计算能力的提升,密钥长度越长越安全(常用的是 2048 位或以上)。以下为生成公钥、私钥的工作原理:

非对称加密:ECDHE
ECDHE(Elliptic Curve Diffie-Hellman Ephemeral,椭圆曲线迪菲-赫尔曼密钥交换) 是一种基于椭圆曲线密码学的密钥交换算法,用于在不安全的网络中安全地协商共享密钥。它是迪菲-赫尔曼密钥交换(Diffie-Hellman Key Exchange, DH) 的升级版,结合了椭圆曲线密码学(ECC)的高效性和前向安全性(Forward Secrecy)。
前向安全性:每次会话使用临时密钥(Ephemeral Key),即使服务器的私钥泄露,之前的通信也无法被解密。
密钥长度短:椭圆曲线密码学(ECC)在相同安全强度下,所需的密钥长度比 RSA 和传统 DH 更短,计算效率更高。
安全性:基于椭圆曲线的离散对数问题(ECDLP),目前没有已知的有效攻击方法。
在一个会话中的加密通信分五步:
选择椭圆曲线参数:双方约定一组椭圆曲线的数学参数(如曲线方程x25519 计算速度快 密钥长度短、基点和阶数),作为密钥交换的基础。
生成临时密钥对:客户端和服务器各自生成一对临时密钥(临时私钥和临时公钥),临时私钥是随机数,临时公钥是通过临时私钥和基点计算得出的。
交换临时公钥:客户端和服务器将自己的临时公钥发送给对方,用于后续计算共享密钥。
计算临时共享密钥:客户端和服务器使用对方的临时公钥和自己的临时私钥,通过椭圆曲线上的数学运算计算出相同的临时共享密钥。
生成临时会话密钥:共享密钥经过哈希函数处理后,生成最终的临时会话密钥,用于后续的对称加密通信。

1.1.2 SSL/TLS 协议
SSL/TLS是一种密码通信框架,他是世界上使用最广泛的密码通信方法。SSL/TLS综合运用了密码学中的对称密码,消息认证码,公钥密码,数字签名,伪随机数生成器等,可以说是密码学中的集大成者。
TLS(Transport Layer Security,传输层安全)是SSL(Secure Socket Layer,安全套接层)的后续版本。可以使得 TCP 连接安全。
SSL/TLS是一个安全通信框架,上面可以承载HTTP协议或者SMTP/POP3协议等。
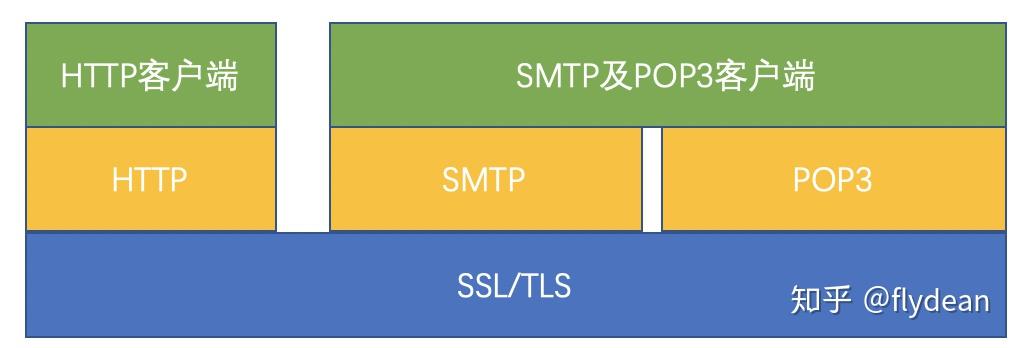
我们来看看 TLS 协议的架构:
TLS记录协议:主要负责使用对称密码对消息进行加密。
TLS握手协议:
握手协议(重点):负责在客户端和服务器端商定密码算法和共享密钥,包括证书认证,是4个协议中最最复杂的部分。
密码规格变更协议:负责向通信对象传达变更密码方式的信号;
警告协议:负责在发生错误的时候将错误传达给对方;
应用数据协议:负责将TLS承载的应用数据传达给通信对象的协议。
前情回顾:
Bob 生成了一对公钥和私钥,将公钥 (e, n) 公开,私钥 (d, n) 自己保存。
Alice 用 Bob 的公钥对消息加密,并把密文发给 Bob。
Bob 收到密文后,用自己的私钥解密,获得原始消息。
TLS 的实现过程如下:
“我要你的公钥”:ClientHello
“好的给你我的公钥,并告诉你加密算法”:ServerHello
“我告诉你我拿到你的公钥了,加密下试试看”:ChangeCipherSpec + Encrypted Handshake Message(Finished)
“好的没问题,我也开始加密了”:ChangeCipherSpec + Encrypted Handshake Message(Finished)
TLS 最终需要约定出来一个临时会话密钥,用于后续对称加密通信,以下为 RSA:
”我生成一个随机数 CR 用于做会话密钥“:ClientHello-Client Random
”我知道随机数 CR 了,我也要生成一个随机数 SR 给你,可以对 CR 混合“:ServerHello-Server Random
”好的,我再生成一个随机数 PR,并且试试你给我的加密算法,看看你能否解密“:Client Key Exchgange
会话密钥(Master Secret) = RSA(Client Random, Server Random, pre-master)
前情回顾 ECDHE:
选择椭圆曲线参数:双方约定一组椭圆曲线的数学参数(如曲线方程x25519、基点和阶数),作为密钥交换的基础。
生成临时密钥对:客户端和服务器各自生成一对临时密钥(临时私钥和临时公钥),临时私钥是随机数,临时公钥是通过临时私钥和基点计算得出的。
交换临时公钥:客户端和服务器将自己的临时公钥发送给对方,用于后续计算共享密钥。
计算临时共享密钥:客户端和服务器使用对方的临时公钥和自己的临时私钥,通过椭圆曲线上的数学运算计算出相同的临时共享密钥。
生成临时会话密钥:共享密钥经过哈希函数处理后,生成最终的临时会话密钥,用于后续的对称加密通信。
而 ECDHE 算法更复杂一些:
”我要你的公钥,生成一个随机数 CR 给你“:ClientHello
”好的,我也要:
生成一个随机数 SR 给你:ServerHello - ServerRandom
我用基点和 SR 算出服务端公钥 SP 给你,同时告诉你加密算法和数学信息“:ServerHello - Server Key Exchange(RSA没有这一步)
”好的,我再生成一个随机数 PR,并且试试你给我的加密算法给你客户端公钥 CP,看看你能否解密“:Client Key Exchgange
ECDHE 算法算出的共享密钥 = ECDHE(CR, SP) = ECDHE(CP, SR)
会话密钥(Master Secret)= 客户端随机数 CR + 服务端随机数 SR + ECDHE 算法算出的共享密钥
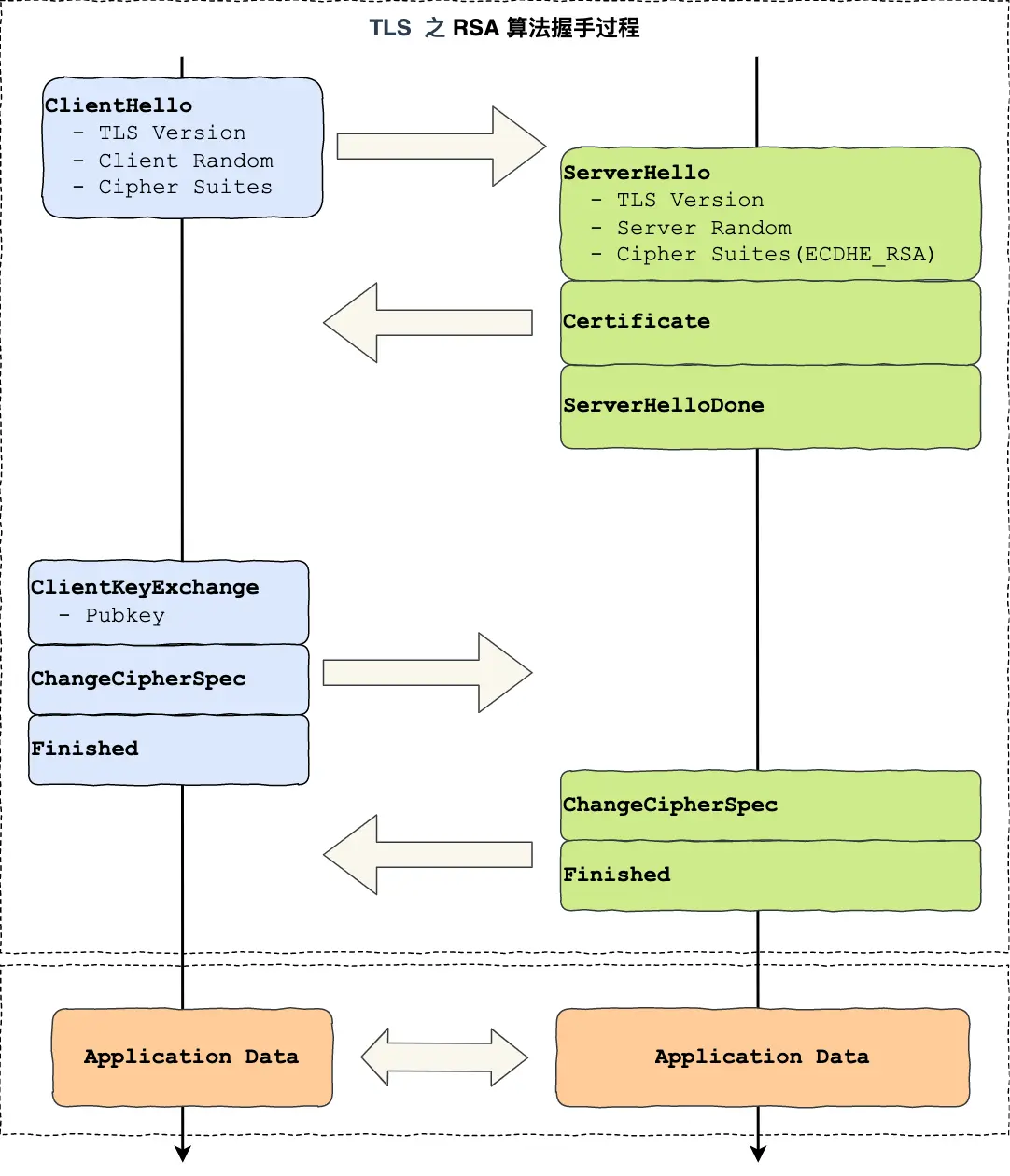

TLS 1.2 支持 RSA 和 ECDHE 算法,而 TLS 1.3 只支持 ECDHE 算法。
1.1.3 数字证书
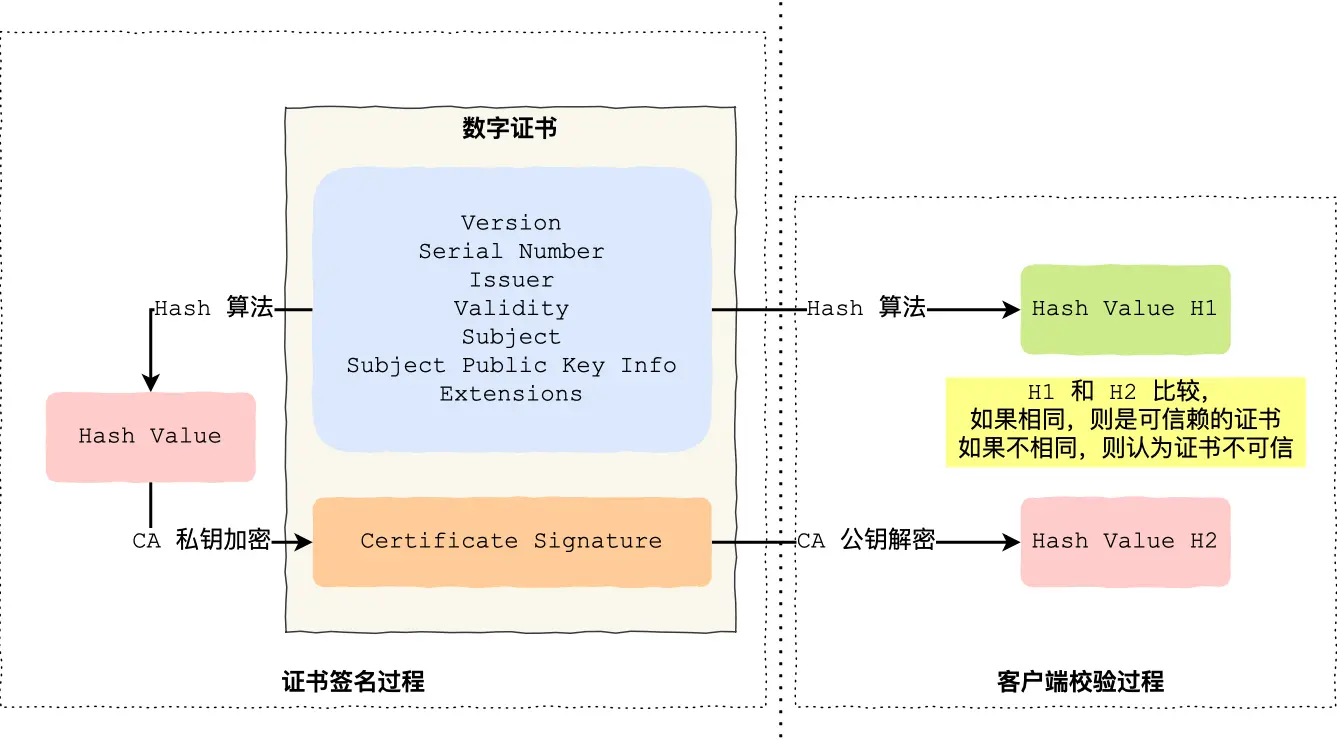
数字证书主要用来认证服务器的身份,即证明服务器给的公钥可信。
为了让服务端的公钥被大家信任,服务端的证书都是由 CA (Certificate Authority,证书认证机构)签名的,CA 就是网络世界里的公安局、公证中心,具有极高的可信度,所以由它来给各个公钥签名,信任的一方签发的证书,那必然证书也是被信任的。我们的浏览器和操作系统也会有相应的 CA 公钥信息。
在 TLS 的 Certificate 阶段,服务端会给一个客户端一个加密的 证书签名 Certificate Signature,其用客户端内置的 CA 公钥信息 就可以得到当前会话公钥等信息的 Hash 值,然后在本地通过相同的计算方法比较,即可验证。
1.1.4 加密哈希签名算法(Signature)
签名的作用可以避免中间人在获取证书时对证书内容的篡改,刚才的证书签名就是一个例子。
除此之外,在 Server Key Exchange 阶段也对服务端椭圆算法公钥做了签名,防止公钥 SP 被篡改:
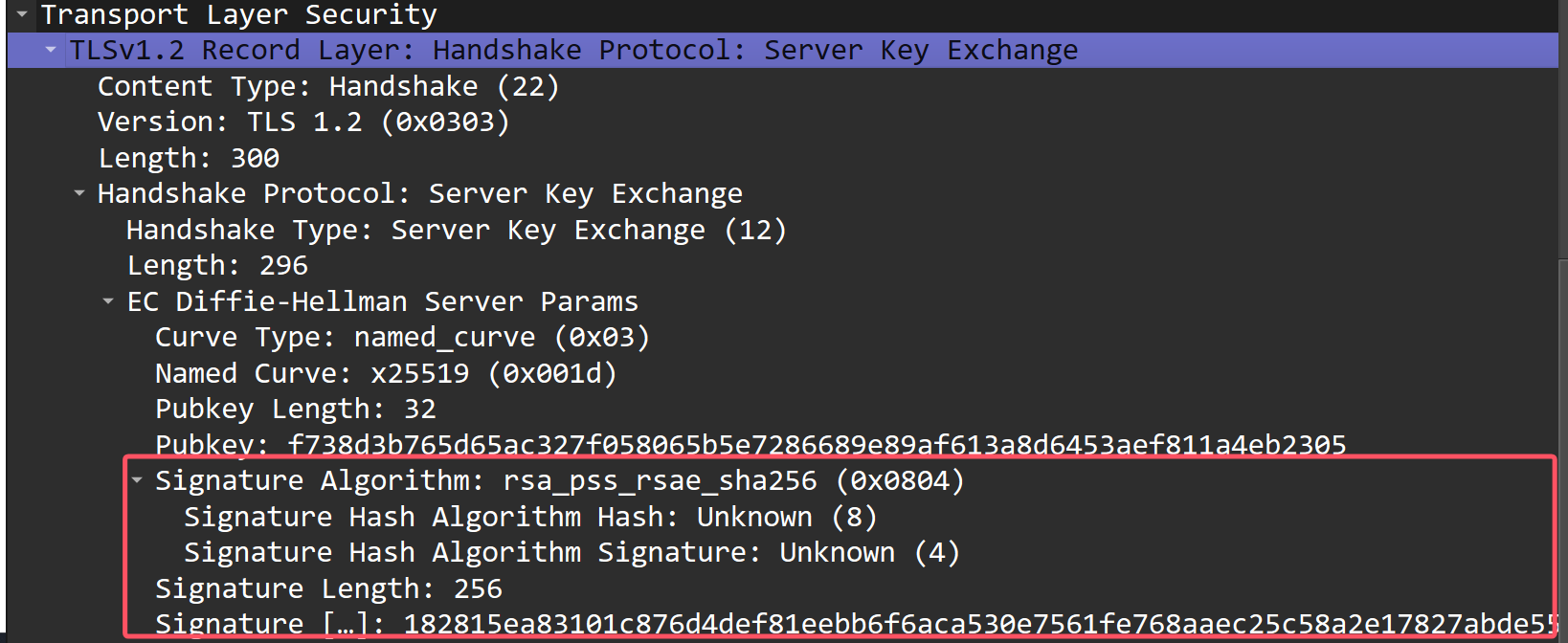
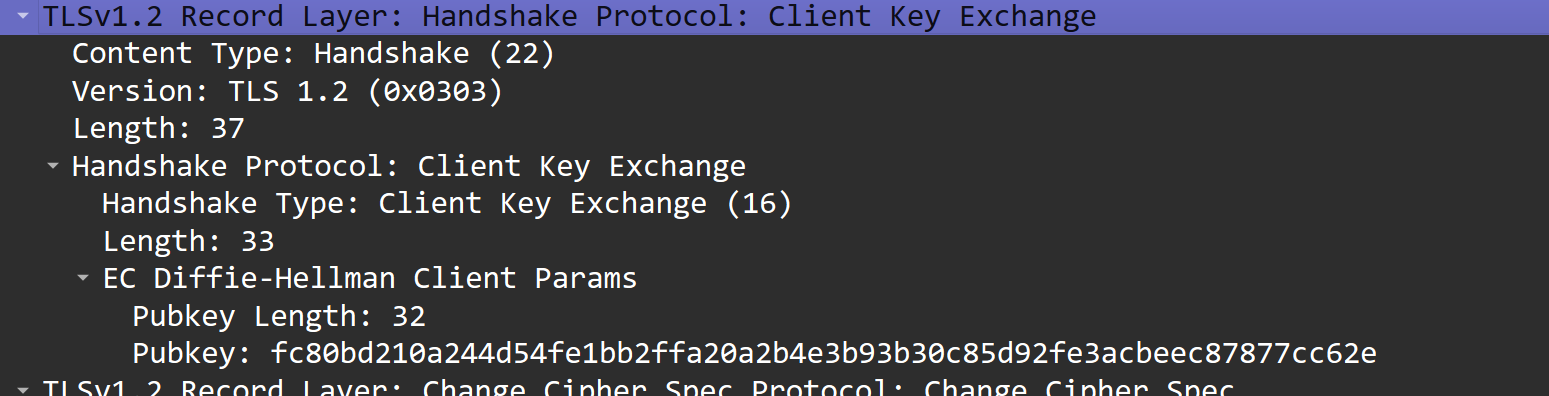
但是我在 Client Key Exchange 阶段没看到签名,不知道这是为什么:
1.2 WebSocket
1.2.1 WebSocket 简单实践
服务端:
import asyncio
import websockets
# 定义 WebSocket 服务端的处理函数
async def handler(websocket):
print(f"New connection from {websocket.remote_address}")
try:
# 持续发送数据给客户端
async def send_data():
count = 0
while True:
await asyncio.sleep(1) # 每秒发送一次数据
message = f"Server message {count}"
await websocket.send(message)
print(f"Sent to client: {message}")
count += 1
# 持续接收客户端的数据
async def receive_data():
while True:
message = await websocket.recv()
print(f"Received from client: {message}")
# 同时运行发送和接收任务
await asyncio.gather(send_data(), receive_data())
except websockets.exceptions.ConnectionClosed:
print(f"Connection closed by {websocket.remote_address}")
# 启动 WebSocket 服务端
async def main():
server = await websockets.serve(handler, "localhost", 8765)
print("WebSocket server started at ws://localhost:8765")
await server.wait_closed()
# 启动事件循环
if __name__ == "__main__":
asyncio.run(main())客户端
import asyncio
import websockets
# 定义 WebSocket 客户端的通信函数
async def client():
uri = "ws://localhost:8765"
async with websockets.connect(uri) as websocket:
# 持续发送数据给服务端
async def send_data():
count = 0
while True:
await asyncio.sleep(1.1) # 每秒发送一次数据
message = f"Client message {count}"
await websocket.send(message)
print(f"Sent to server: {message}")
count += 1
# 持续接收服务端的数据
async def receive_data():
while True:
message = await websocket.recv()
print(f"Received from server: {message}")
# 同时运行发送和接收任务
await asyncio.gather(send_data(), receive_data())
# 启动客户端
if __name__ == "__main__":
asyncio.run(client())之后在做项目的时候再进行最佳实践。
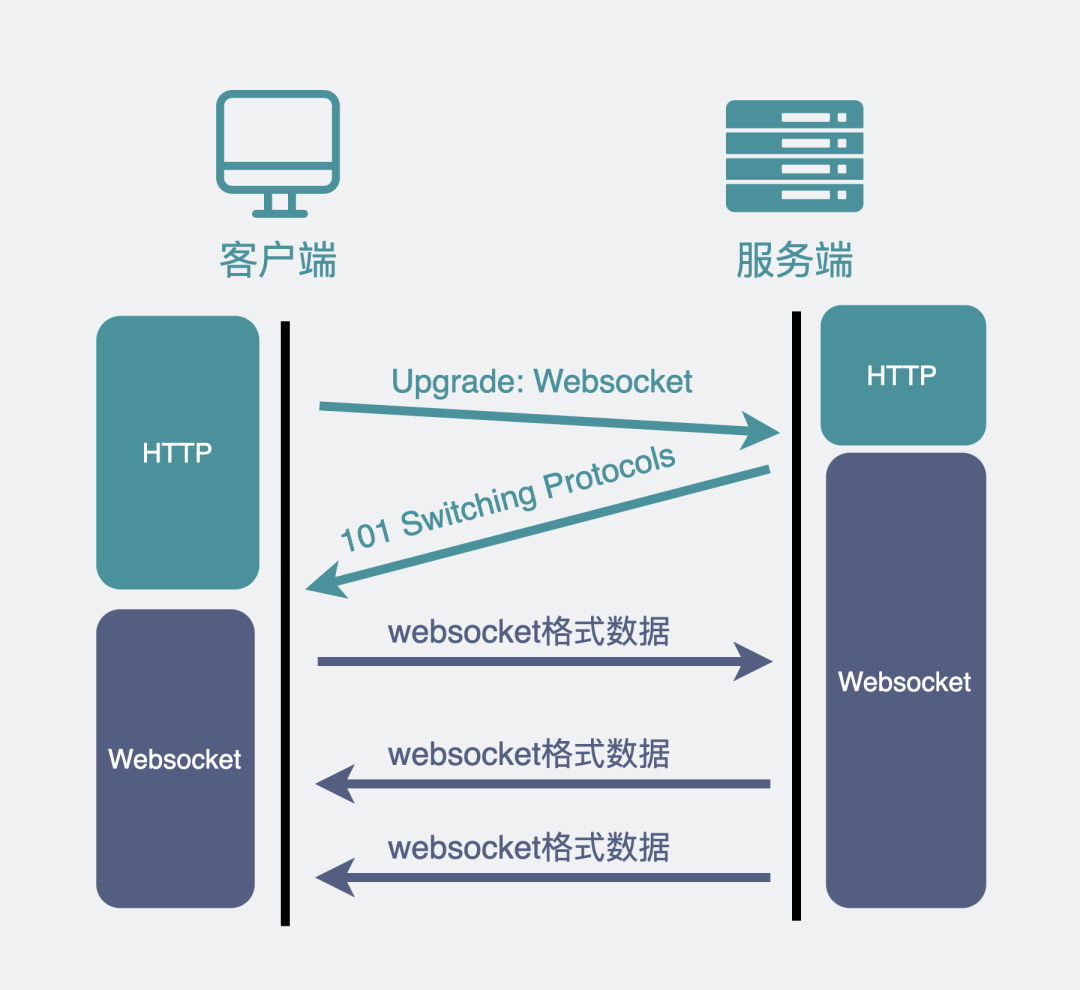
1.2.2 HTTP 协议升级
我们平时刷网页,一般都是在浏览器上刷的,一会刷刷图文,这时候用的是 HTTP 协议,一会打开网页游戏,这时候就得切换成我们新介绍的 WebSocket 协议。
为了兼容这些使用场景。浏览器在 TCP 三次握手建立连接之后,都统一使用 HTTP 协议先进行一次通信。
如果此时是普通的 HTTP 请求,那后续双方就还是老样子继续用普通 HTTP 协议进行交互,这点没啥疑问。
如果这时候是想建立 WebSocket 连接,就会在 HTTP 请求里带上一些特殊的header 头,如下:
Connection: Upgrade
Upgrade: WebSocket
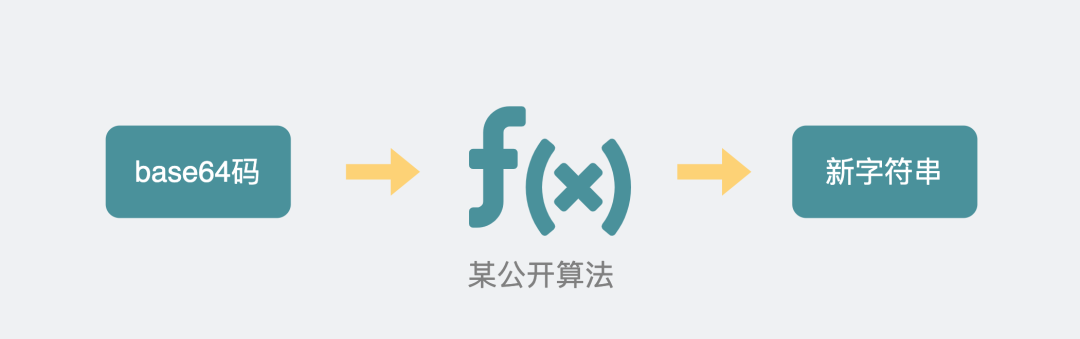
Sec-WebSocket-Key: T2a6wZlAwhgQNqruZ2YUyg==\r\n这些 header 头的意思是,浏览器想升级协议(Connection: Upgrade),并且想升级成 WebSocket 协议(Upgrade: WebSocket)。同时带上一段随机生成的 base64 码(Sec-WebSocket-Key),发给服务器。
如果服务器正好支持升级成 WebSocket 协议。就会走 WebSocket 握手流程,同时根据客户端生成的 base64 码,用某个公开的算法变成另一段字符串,放在 HTTP 响应的 Sec-WebSocket-Accept 头里,同时带上101状态码,发回给浏览器。HTTP 的响应如下:
HTTP/1.1 101 Switching Protocols\r\n
Sec-WebSocket-Accept: iBJKv/ALIW2DobfoA4dmr3JHBCY=\r\n
Upgrade: WebSocket\r\n
Connection: Upgrade\r\nHTTP 状态码=200(正常响应)的情况,大家见得多了。101 确实不常见,它其实是指协议切换。
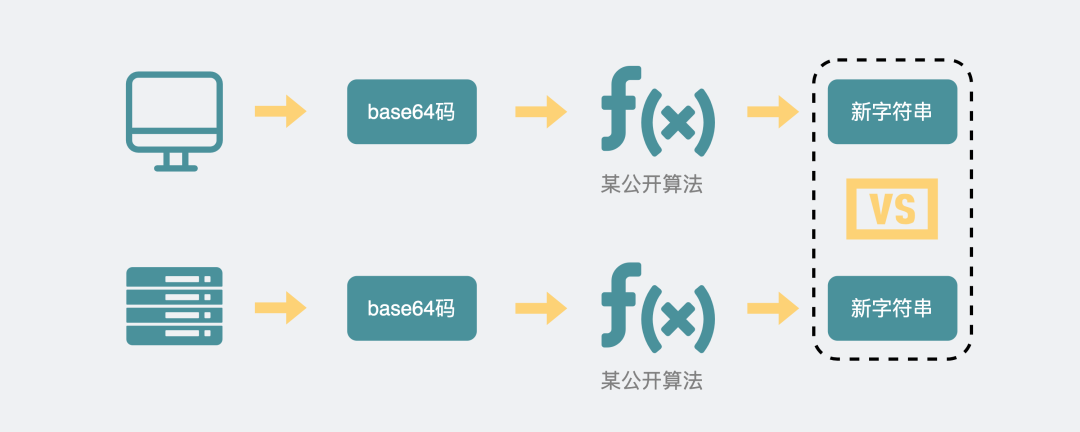
之后,浏览器也用同样的公开算法将base64码转成另一段字符串,如果这段字符串跟服务器传回来的字符串一致,那验证通过。
就这样经历了一来一回两次 HTTP 握手,WebSocket就建立完成了,后续双方就可以使用 webscoket 的数据格式进行通信了。
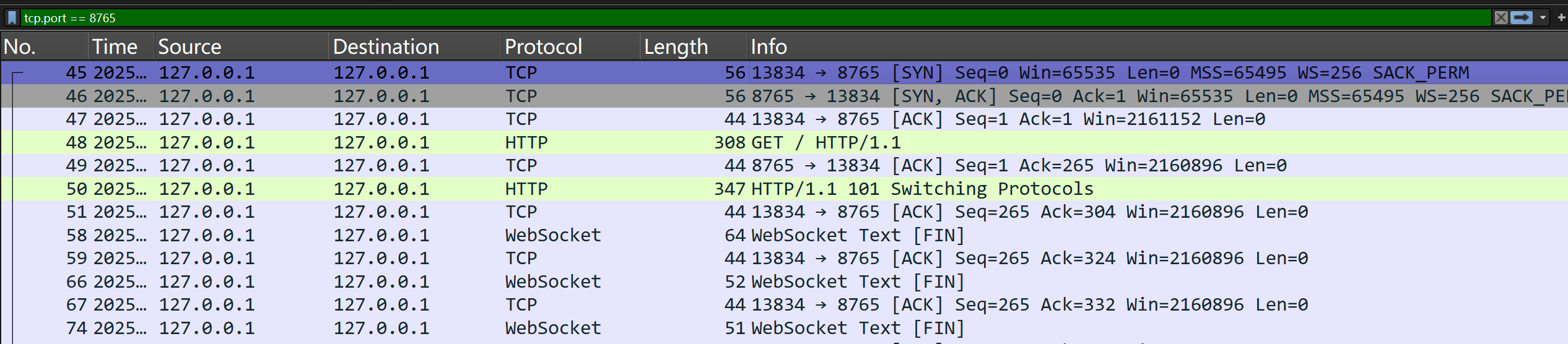
抓包可知如下:
感谢小林Coding,让我20分钟就学完了WebSocket原理。
1.3 RPC
RPC 就是对 TCP、UDP 等协议进行拼凑组合和改装升级,比如把字节流的边界重新定义、重新进行服务发现等等,组成一个船新的通信协议。
其实 http 就算一种 RPC,刘硕的 MyRPC (LSP?)也是他对 TCP 连接 (Netty实现) 来做的各种组件。
https://xiaolincoding.com/network/2_http/http_rpc.html
好像除了纷享销客这个公司,每个大公司都不太喜欢用http,他们都实现了自己的 RPC ,常见的 RPC 框架包括:
gRPC:由Google开发,基于HTTP/2和Protocol Buffers,支持多种语言,性能优异。
Apache Thrift:由Facebook开发,支持多种语言和传输协议,适用于跨语言服务开发。
Dubbo:阿里巴巴开源的 Java RPC 框架,提供丰富的服务治理功能,广泛应用于微服务架构。
Spring Cloud Netflix:基于Spring Cloud生态,集成Eureka、Ribbon等组件,适合构建微服务。
Finagle:Twitter开发的Scala RPC框架,支持异步编程和高并发,适合构建分布式系统。
JSON-RPC:轻量级RPC协议,使用JSON格式传输数据,易于实现和调试。
1.3.1 gRPC 序列化
序列化方式:Protocol Buffers (Protobuf)
原理:
Protobuf 是一种二进制序列化格式,通过
.proto文件定义数据结构和接口。使用字段编号(tag)来标识字段,而不是字段名,因此序列化后的数据非常紧凑。
支持向前和向后兼容(通过字段编号和版本控制)。
特点:
高效:序列化和反序列化速度快,数据体积小。
跨语言:通过
.proto文件生成多种语言的代码。强类型:数据结构在
.proto文件中明确定义,减少运行时错误。
使用场景:
高性能、低延迟的通信场景。
需要跨语言支持的微服务架构。
适合流式传输(如实时通信、流数据处理)。
示例:
1. 定义 .proto 文件
syntax = "proto3";
package example;
service Greeter {
rpc SayHello (HelloRequest) returns (HelloResponse);
}
message HelloRequest {
string name = 1;
}
message HelloResponse {
string message = 2;
}2. 生成 Java 代码
使用 protoc 工具生成 Java 代码:
protoc --java_out=. greeter.proto3. 实现服务端(Java)
import io.grpc.Server;
import io.grpc.ServerBuilder;
import io.grpc.stub.StreamObserver;
import example.GreeterGrpc;
import example.HelloRequest;
import example.HelloResponse;
import java.io.IOException;
public class GreeterServer {
public static void main(String[] args) throws IOException, InterruptedException {
Server server = ServerBuilder.forPort(50051)
.addService(new GreeterImpl())
.build()
.start();
System.out.println("Server is running on port 50051...");
server.awaitTermination();
}
static class GreeterImpl extends GreeterGrpc.GreeterImplBase {
@Override
public void sayHello(HelloRequest req, StreamObserver<HelloResponse> responseObserver) {
HelloResponse reply = HelloResponse.newBuilder()
.setMessage("Hello, " + req.getName())
.build();
responseObserver.onNext(reply);
responseObserver.onCompleted();
}
}
}4. 实现客户端(Java)
import io.grpc.ManagedChannel;
import io.grpc.ManagedChannelBuilder;
import example.GreeterGrpc;
import example.HelloRequest;
import example.HelloResponse;
public class GreeterClient {
public static void main(String[] args) {
ManagedChannel channel = ManagedChannelBuilder.forAddress("localhost", 50051)
.usePlaintext()
.build();
GreeterGrpc.GreeterBlockingStub stub = GreeterGrpc.newBlockingStub(channel);
HelloRequest request = HelloRequest.newBuilder()
.setName("World")
.build();
HelloResponse response = stub.sayHello(request);
System.out.println("Response: " + response.getMessage());
channel.shutdown();
}
}1.3.2 Apache Thrift 序列化
支持的序列化方式:
Binary Protocol:
使用二进制格式,性能高,体积小。
Compact Protocol:
压缩的二进制格式,比 Binary Protocol 更节省空间。
JSON Protocol:
使用 JSON 格式,可读性好,但性能较低。
其他格式:
Thrift 支持自定义序列化方式。
特点:
灵活性:支持多种序列化方式,适应不同场景。
跨语言:通过
.thrift文件生成多种语言的代码。性能:Binary Protocol 和 Compact Protocol 性能优异,适合高性能场景。
使用场景:
跨语言服务开发。
需要灵活选择序列化方式的场景。
适合调试(使用 JSON Protocol)或高性能(使用 Binary/Compact Protocol)。
示例:
1. 定义 .thrift 文件
namespace java example
service Greeter {
string sayHello(1: string name)
}2. 生成 Java 代码
使用 Thrift 编译器生成 Java 代码:
thrift --gen java greeter.thrift3. 实现服务端(Java)
import org.apache.thrift.server.TServer;
import org.apache.thrift.server.TSimpleServer;
import org.apache.thrift.transport.TServerSocket;
import org.apache.thrift.transport.TServerTransport;
import example.Greeter;
import example.Greeter.Iface;
public class GreeterServer {
public static class GreeterHandler implements Iface {
@Override
public String sayHello(String name) {
return "Hello, " + name;
}
}
public static void main(String[] args) {
try {
GreeterHandler handler = new GreeterHandler();
Greeter.Processor<Iface> processor = new Greeter.Processor<>(handler);
TServerTransport serverTransport = new TServerSocket(9090);
TServer server = new TSimpleServer(new TServer.Args(serverTransport).processor(processor));
System.out.println("Server is running on port 9090...");
server.serve();
} catch (Exception e) {
e.printStackTrace();
}
}
}4. 实现客户端(Java)
import org.apache.thrift.TException;
import org.apache.thrift.protocol.TBinaryProtocol;
import org.apache.thrift.protocol.TProtocol;
import org.apache.thrift.transport.TSocket;
import org.apache.thrift.transport.TTransport;
import example.Greeter;
public class GreeterClient {
public static void main(String[] args) {
try (TTransport transport = new TSocket("localhost", 9090)) {
transport.open();
TProtocol protocol = new TBinaryProtocol(transport);
Greeter.Client client = new Greeter.Client(protocol);
String res = client.sayHello("World");
System.out.println("Response: " + res);
} catch (TException e) {
e.printStackTrace();
}
}
}1.3.3 Dubbo 序列化
支持的序列化方式:
Hessian2(默认):
基于二进制的轻量级序列化协议,性能较好。
Java 原生序列化:
使用 Java 自带的序列化机制,兼容性好,但性能较差。
JSON:
可读性好,但性能较低。
Kryo:
高性能的二进制序列化框架,适合对性能要求极高的场景。
Protobuf:
支持 Google 的 Protocol Buffers,性能优异。
其他:
Dubbo 还支持 Avro、FST 等序列化方式。
特点:
丰富性:支持多种序列化方式,适应不同场景。
性能:Hessian2 和 Kryo 性能优异,适合高性能场景。
Java 生态:对 Java 支持非常好,尤其是 Hessian2 和 Kryo。
使用场景:
Java 生态下的微服务架构。
需要丰富序列化选项的场景。
适合大规模分布式系统,尤其是电商、金融等领域。
示例:
1. 定义接口(Java)
public interface Greeter {
String sayHello(String name);
}2. 实现服务端(Java)
import org.apache.dubbo.config.ApplicationConfig;
import org.apache.dubbo.config.RegistryConfig;
import org.apache.dubbo.config.ServiceConfig;
import java.util.concurrent.CountDownLatch;
public class GreeterServer {
public static void main(String[] args) throws InterruptedException {
ServiceConfig<Greeter> service = new ServiceConfig<>();
service.setApplication(new ApplicationConfig("greeter-server"));
service.setRegistry(new RegistryConfig("zookeeper://127.0.0.1:2181"));
service.setInterface(Greeter.class);
service.setRef(new GreeterImpl());
service.export();
System.out.println("Server is running...");
new CountDownLatch(1).await(); // 保持服务运行
}
static class GreeterImpl implements Greeter {
@Override
public String sayHello(String name) {
return "Hello, " + name;
}
}
}3. 实现客户端(Java)
import org.apache.dubbo.config.ApplicationConfig;
import org.apache.dubbo.config.ReferenceConfig;
import org.apache.dubbo.config.RegistryConfig;
public class GreeterClient {
public static void main(String[] args) {
ReferenceConfig<Greeter> reference = new ReferenceConfig<>();
reference.setApplication(new ApplicationConfig("greeter-client"));
reference.setRegistry(new RegistryConfig("zookeeper://127.0.0.1:2181"));
reference.setInterface(Greeter.class);
Greeter greeter = reference.get();
String res = greeter.sayHello("World");
System.out.println("Response: " + res);
}
}2. 网络命令大杂烩
这个部分就应该大一的时候去学,工欲善其事必先利其器!
2.1 网络抓包
在计算机领域,dump一般译作转储。即使翻译的很贴切,但还是很难从字面上完全理解dump的真正含义。
dump有动词和名词两种场景。作为动词,你可以从dump的目的和dump的对象这两个方面去理解dump本身。
为什么要dump(dump的目的)?因为程序在计算机中运行时,在内存、CPU、I/O等设备上的数据都是动态的(或者说是易失的),也就是说数据使用完或者发生异常就会丢掉。如果我想得到某些时刻的数据(有可能是调试程序Bug或者收集某些信息),就要把他转储(dump)为静态(如文件)的形式。否则,这些数据你永远都拿不到。
dump转储的是什么内容(dump的对象)?其实上边已经提到了,就是将动态(易失)的数据,保存为静态的数据(持久数据)。像程序这种本来就保存在存储介质(如硬盘)中的数据,也就没有必要dump。
现在,dump作为名词也很好理解了,一般就是指dump(动词)的结果文件。常出现dump的场景:Unix/Linux中的coredump,Java中的headdump和threaddump,还有就是tcpdump工具。
原文链接:https://blog.csdn.net/Dontla/article/details/121694273
2.1.1 工具简介
两种工具的使用教程:
WireShark(Windows - GUI):网络顶级掠食者 Wireshark抓包从入门到实战
tcpdump(Linux - 终端)
WireShark
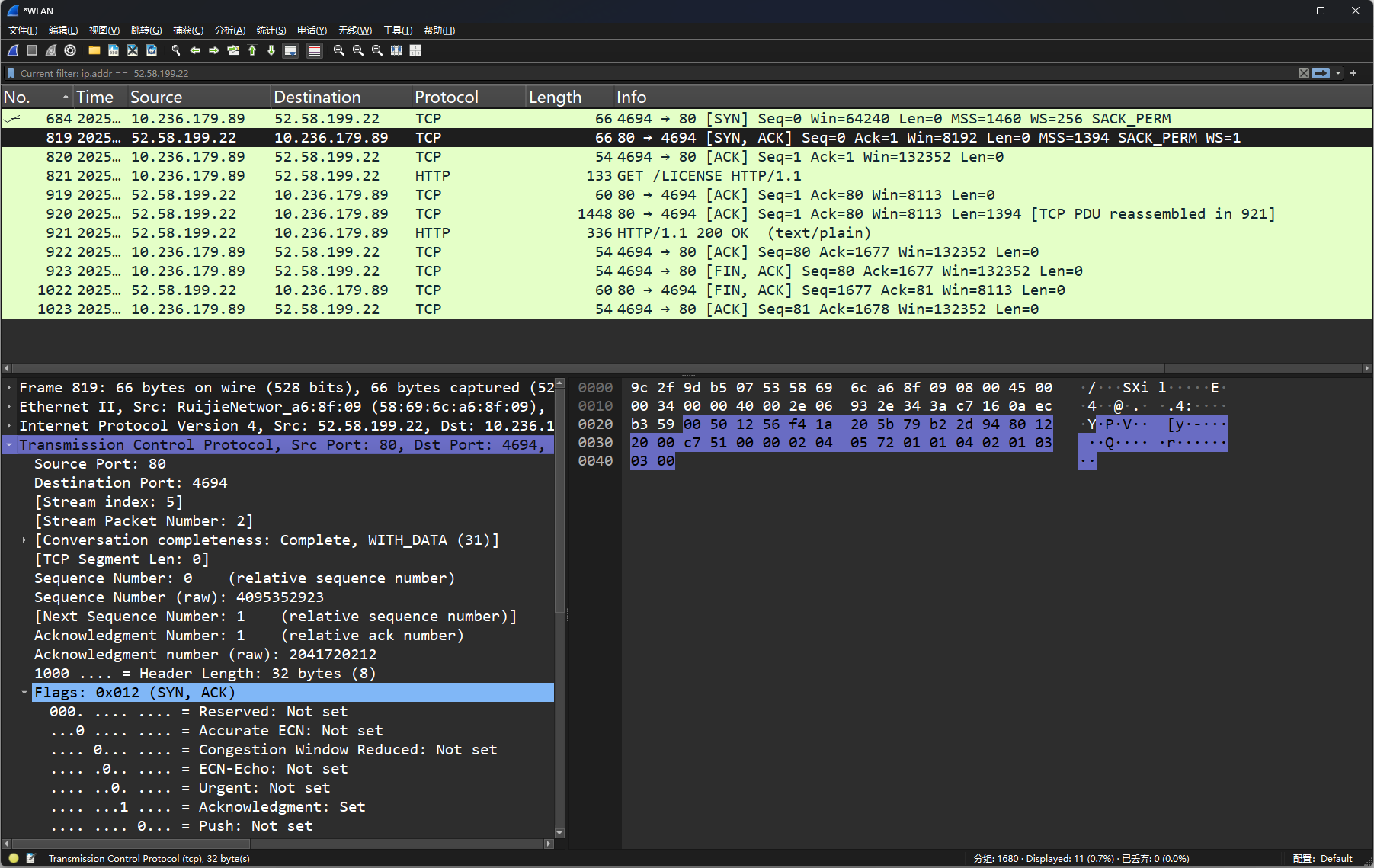
首先我们看列标题分析:
No.
数据包的编号(从捕获到的数据包按顺序排列)。Time
数据包被捕获的时间,以秒为单位,从捕获开始计算。Source
数据包的源 IP 地址或主机地址(例如10.236.179.89)。Destination
数据包的目标 IP 地址或主机地址(例如52.58.199.22)。Protocol
数据包使用的协议(例如TCP、HTTP)。Length
数据包的总长度(以字节为单位,例如66字节)。Info
数据包的额外信息,通常描述其功能或状态。例如:[SYN]表示 TCP 连接的同步请求包。[SYN, ACK]表示同步请求确认包。[ACK]表示确认包。HTTP/1.1 200 OK表示 HTTP 请求的正常响应。
以下是几条关键数据包的分析:
编号 819:
描述: 这是一个 TCP
SYN, ACK包,表示服务器确认客户端的同步请求。源地址(Source):
52.58.199.22(服务器)。目标地址(Destination):
10.236.179.89(客户端)。源端口: 80(HTTP 默认端口)。
目标端口: 4694(客户端随机分配的端口)。
编号 912:
描述: HTTP 请求返回
200 OK,表示请求成功,内容为文本类型(text/plain)。
编号 1023:
描述: 一个
ACK包,表示连接关闭。
各层内容分析:
Frame 819:
数据包的整体信息:66 bytes on wire:数据包在网络上传输的大小为 66 字节。Capture size: 66 bytes:实际捕获的大小为 66 字节。
Ethernet II:
这是数据链路层协议,用于描述以太网帧的内容:Source:
RuijieNetwork_a6:8f:89(源 MAC 地址)。Destination:
RuijieNetwork_69:6c:6c(目标 MAC 地址)。
Internet Protocol Version 4 (IPv4):
网络层协议,用于描述数据包的 IP 信息:Source Address:
52.58.199.22(源 IP)。Destination Address:
10.236.179.89(目标 IP)。
Transmission Control Protocol (TCP):
传输层协议,用于描述 TCP 连接的具体信息:Source Port: 80(服务器端口)。
Destination Port: 4694(客户端端口)。
Flags:
0x12,表示SYN, ACK包,用于连接建立。
底部的原始数据:底部是选中数据包的原始十六进制数据和对应的 ASCII 解码内容。以下是关键部分:
左侧: 数据的十六进制表示(例如
58 69 6c a6 8f)。右侧: 数据的 ASCII 解码部分(例如
Xi表示 ASCII 字符)。
对于这部分,通常需要结合协议格式说明来解析数据字段。
tcpdump
至于 tcpdump, 首先执行
$ sudo tcpdump host 3.125.197.172
tcpdump: verbose output suppressed, use -v[v]... for full protocol decode
listening on eth0, link-type EN10MB (Ethernet), snapshot length 262144 bytes发完 curl 之后显示一些抓包的信息:
tcpdump: verbose output suppressed, use -v[v]... for full protocol decode
listening on eth0, link-type EN10MB (Ethernet), snapshot length 262144 bytes
02:33:35.464035 IP 172.17.156.11.58432 > ec2-3-125-197-172.eu-central-1.compute.amazonaws.com.http: Flags [S], seq 44634848, win 64240, options [mss 1460,sackOK,TS val 4042258912 ecr 0,nop,wscale 7], length 0
02:33:35.684091 IP ec2-3-125-197-172.eu-central-1.compute.amazonaws.com.http > 172.17.156.11.58432: Flags [S.], seq 1840050780, ack 44634849, win 8192, options [mss 1394,sackOK,TS val 1169613718 ecr 4042258912,nop,wscale 0], length 0
02:33:35.684146 IP 172.17.156.11.58432 > ec2-3-125-197-172.eu-central-1.compute.amazonaws.com.http: Flags [.], ack 1, win 502, options [nop,nop,TS val 4042259132 ecr 1169613718], length 0
02:33:35.684212 IP 172.17.156.11.58432 > ec2-3-125-197-172.eu-central-1.compute.amazonaws.com.http: Flags [P.], seq 1:81, ack 1, win 502, options [nop,nop,TS val 4042259132 ecr 1169613718], length 80: HTTP: GET /LICENSE HTTP/1.1
02:33:35.900489 IP ec2-3-125-197-172.eu-central-1.compute.amazonaws.com.http > 172.17.156.11.58432: Flags [.], ack 81, win 8112, options [nop,nop,TS val 1169613936 ecr 4042259132], length 0
02:33:35.900489 IP ec2-3-125-197-172.eu-central-1.compute.amazonaws.com.http > 172.17.156.11.58432: Flags [P.], seq 1:1677, ack 81, win 8112, options [nop,nop,TS val 1169613936 ecr 4042259132], length 1676: HTTP: HTTP/1.1 200 OK
02:33:35.900518 IP 172.17.156.11.58432 > ec2-3-125-197-172.eu-central-1.compute.amazonaws.com.http: Flags [.], ack 1677, win 499, options [nop,nop,TS val 4042259348 ecr 1169613936], length 0
02:33:35.900765 IP 172.17.156.11.58432 > ec2-3-125-197-172.eu-central-1.compute.amazonaws.com.http: Flags [F.], seq 81, ack 1677, win 501, options [nop,nop,TS val 4042259348 ecr 1169613936], length 0
02:33:36.114566 IP ec2-3-125-197-172.eu-central-1.compute.amazonaws.com.http > 172.17.156.11.58432: Flags [F.], seq 1677, ack 82, win 8112, options [nop,nop,TS val 1169614152 ecr 4042259348], length 0
02:33:36.114594 IP 172.17.156.11.58432 > ec2-3-125-197-172.eu-central-1.compute.amazonaws.com.http: Flags [.], ack 1678, win 501, options [nop,nop,TS val 4042259562 ecr 1169614152], length 0另外我们也可以将 tcpdump 抓到的包放到 WireShark 中进行解析:
$ sudo tcpdump -s0 -c 1000 -nn -w ./a.cap host 3.125.197.172 sudo: 以超级用户权限运行命令,因为捕获网络流量通常需要较高的权限。tcpdump: 一个常用的网络数据包捕获工具,用于捕获和分析网络流量。-s0: 设置捕获的数据包大小为默认的 262144 字节(即不截断数据包)。-s0表示捕获完整的数据包。-c 1000: 捕获 1000 个数据包后停止捕获。-nn: 不解析主机名和端口号。-n表示不将 IP 地址解析为主机名,第二个-n表示不将端口号解析为服务名称。-w ./a.cap: 将捕获的数据包写入文件./a.cap。-w选项指定输出文件。host 3.125.197.172: 只捕获与 IP 地址3.125.197.172相关的流量。host过滤器用于指定要捕获流量的主机。
总结来说,这个命令会捕获与 IP 地址 3.125.197.172 相关的网络流量,捕获 1000 个完整的数据包,并将这些数据包保存到当前目录下的 a.cap 文件中。这个文件可以稍后使用 tcpdump 或其他网络分析工具(如 Wireshark)进行分析。

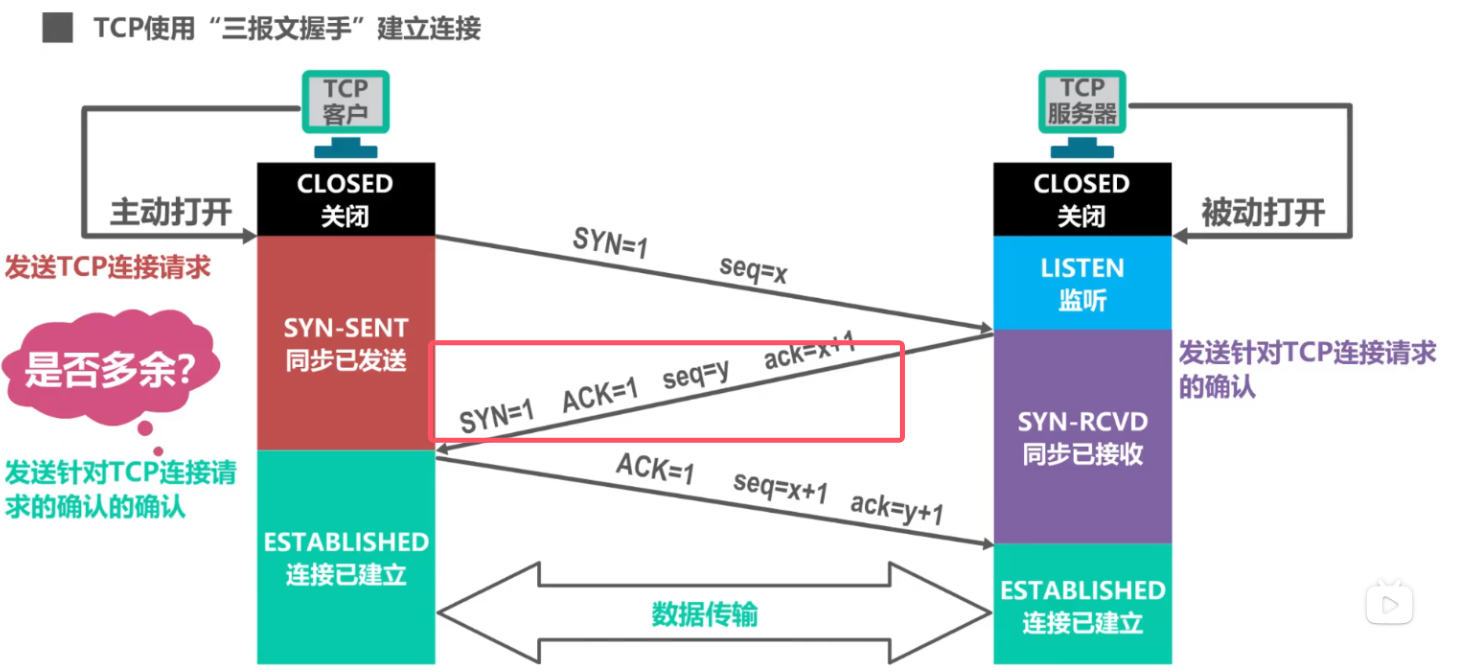
2.1.2 抓取 TCP 三次握手四次挥手
我们尝试抓取一下 HTTP 协议中的 TCP 三次握手和四次挥手协议,以 nginx 的官网为例:
我们先看一下 nginx 官网的 ipv4:
C:\Users\Donnie>nslookup nginx.org
服务器: UnKnown
Address: 172.26.26.3
非权威应答:
名称: nginx.org
Addresses: 2a05:d014:5c0:2600::6
2a05:d014:5c0:2601::6
52.58.199.22
3.125.197.172然后,我们在 Wireshark 中针对 ipv4 进行过滤(二选一,总有一个能获取到):
ip.addr == 52.58.199.22开始抓包后,执行 curl 命令:
C:\Users\Donnie>curl http://nginx.org/LICENSE
/*
* Copyright (C) 2002-2021 Igor Sysoev
* Copyright (C) 2011-2024 Nginx, Inc.
* All rights reserved.
*
* Redistribution and use in source and binary forms, with or without
* modification, are permitted provided that the following conditions
* are met:
* 1. Redistributions of source code must retain the above copyright
* notice, this list of conditions and the following disclaimer.
* 2. Redistributions in binary form must reproduce the above copyright
* notice, this list of conditions and the following disclaimer in the
* documentation and/or other materials provided with the distribution.
*
* THIS SOFTWARE IS PROVIDED BY THE AUTHOR AND CONTRIBUTORS ``AS IS'' AND
* ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
* IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE
* ARE DISCLAIMED. IN NO EVENT SHALL THE AUTHOR OR CONTRIBUTORS BE LIABLE
* FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL
* DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS
* OR SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION)
* HOWEVER CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT
* LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY
* OUT OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF
* SUCH DAMAGE.
*/我们可以在 WireShark 中看到如下界面:
可以清晰地看出三次握手、四次挥手(其实是三次,1022中,服务端向客户端的两次挥手被合并)的过程。
数据包 684 、819、820:三次握手中的
SYN和SYN, ACK和ACK数据包 921:HTTP 请求响应。
数据包 923、1022、1023:四次挥手的
FIN, ACKFIN, ACKACK。
实际上,上面这张图的每一个细节都很重要,这里只针对本图(上文全过程 + 下文819号)进行分析。
1. Source Port【80】:发送端的端口号
2. Destination Port【4694】: 接收端的端口号(随机分配的临时端口)
3. Stream index【5】: 当前 TCP 会话的编号,用于标识属于同一个会话的数据包流。
4. Stream Packet Number【2】: 该数据包在当前 TCP 流中是第 2 个数据包。
5. Conversation completeness【Complete, WITH_DATA (31)】: Wireshark 对当前 TCP 会话的状态描述,表示会话完整并已包含实际数据。
6. TCP Segment Len【0】: 当前 TCP 段的数据负载长度为 0(仅用于传输控制信息,没有携带实际数据)。
7. Sequence Number【raw: 4095353923, relative: 0】: 当前 TCP 段的序列号,用于字节流的顺序控制,此处是初始序列号。
8. Next Sequence Number【raw: 4095353924, relative: 1】: 下一个期望发送的字节序列号,此段无数据负载,因此为 Sequence Number + 1。
9. Acknowledgment Number【raw: 2041720212, relative: 1】: 确认号,表示接收到对端数据后的下一个期望序列号。
10. Header Length【32 bytes (8)】: TCP 头部长度,单位为字节,每个单位为 4 字节,此处总长度为 32 字节。
11. Flags【0x12 (SYN, ACK)】: TCP 标志字段,表示此包用于连接建立,包含同步 (SYN) 和确认 (ACK) 标志。
12. Window【8192】: 接收窗口大小,用于流量控制,表示当前接收方可接受的最大字节数。
13. Calculated Window Size【8192】: 扩展计算后的接收窗口大小,与 Window 字段一致。
14. Checksum【0xc751】: TCP 校验和,用于验证数据包的完整性。此处为未验证 (unverified),Wireshark 未计算校验。
15. Urgent Pointer【0】: 紧急指针字段未设置,表示未使用优先数据指针。
16. Options【12 bytes】: TCP 选项字段,包含:最大分段大小 (MSS) 为 1394 字节、填充字段 (NOP)、选择性确认 (SACK) 支持等信息。
有的时候也会出些意外情况:
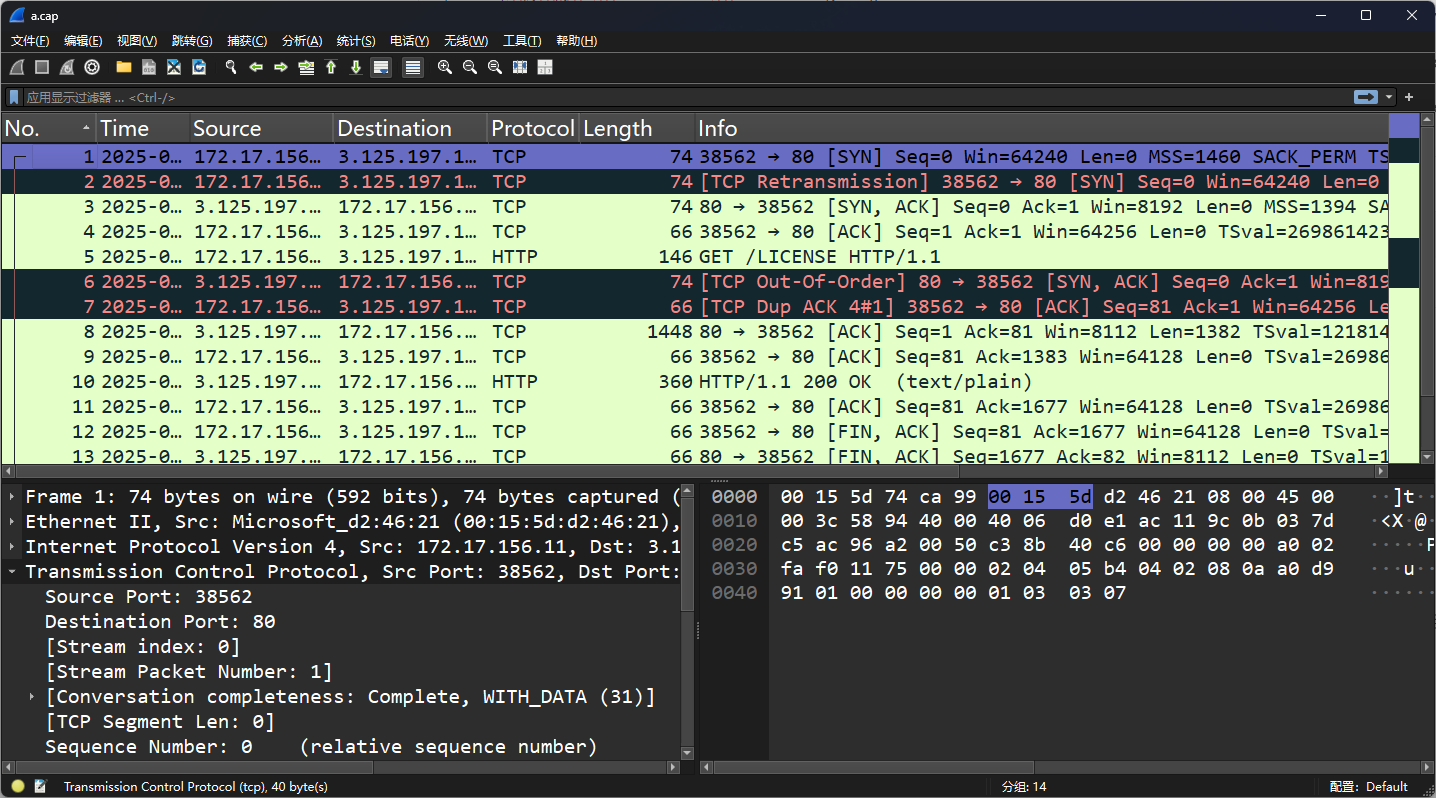
TCP重传(Retransmission):源IP地址172.17.156.11尝试向目的IP地址3.125.197.172的80端口(通常用于HTTP服务)发送一个SYN包,以初始化一个TCP连接。Seq=0表示这是序列号的开始,Win=64240是窗口大小,MSS=1460是最大报文段长度,TSval和TSecr是时间戳值,用于计算往返时间RTT。
"TCP Out-Of-Order" 指的是在TCP传输过程中,接收到的数据包的序列号小于预期的序列号,这通常发生在数据包乱序的情况下。这种现象可能与网络拥塞或数据包在不同路径上传输有关,导致它们不能按照发送顺序到达目的地。在这种情况下,TCP会尝试重新排序这些数据包,以确保数据的完整性和正确性;
"Dup ACK"(重复确认)是指接收方收到一个或多个数据包后,发送一个或多个具有相同确认号(Ack)的ACK包给发送方。这通常发生在接收方检测到数据包丢失或乱序时,通过发送重复的ACK来提示发送方可能存在问题。"4#1" 表示接收方已经四次发送了针对序列号4的ACK,这是第一次重复。这通常是TCP快速重传算法的一部分,用于在没有收到预期数据包时,提示发送方可能需要重传丢失的数据包。
2.2 网络配置
ifconfig 和 ip 是两个用于管理和配置网络接口的命令行工具,通常在 Linux 系统中使用。它们的功能有一些重叠,但 ip 命令被认为是更现代和功能更强大的工具,逐渐取代了 ifconfig。
ifconfig:网络接口配置
ifconfig 是一个传统的命令,用于显示和配置网络接口的信息。它可以用来查看当前网络接口的状态、配置 IP 地址、启用或禁用网络接口等。
查看所有网络接口的信息:这会显示所有网络接口的详细信息,包括 IP 地址、MAC 地址、网络状态等。
$ ifconfig eth0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500 inet 172.17.156.11 netmask 255.255.240.0 broadcast 172.17.159.255 inet6 fe80::215:5dff:fed2:4621 prefixlen 64 scopeid 0x20<link> ether 00:15:5d:d2:46:21 txqueuelen 1000 (以太网) RX packets 6375 bytes 2077647 (2.0 MB) RX errors 0 dropped 0 overruns 0 frame 0 TX packets 4859 bytes 439518 (439.5 KB) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0 lo: flags=73<UP,LOOPBACK,RUNNING> mtu 65536 inet 127.0.0.1 netmask 255.0.0.0 inet6 ::1 prefixlen 128 scopeid 0x10<host> loop txqueuelen 1000 (本地环回) RX packets 11 bytes 1897 (1.8 KB) RX errors 0 dropped 0 overruns 0 frame 0 TX packets 11 bytes 1897 (1.8 KB) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0如果
TX(发送) 和RX(接收) 部分中 errors、dropped、overruns、carrier 以及 collisions 等指标不为 0 时,则说明网络发送或者接收出问题了。查看特定网络接口的信息:
$ ifconfig eth0这会显示
eth0接口的详细信息。启用或禁用网络接口:
ifconfig eth0 up ifconfig eth0 downup启用eth0接口,down禁用eth0接口。配置 IP 地址:
ifconfig eth0 192.168.1.100 netmask 255.255.255.0这会将
eth0接口的 IP 地址设置为192.168.1.100,子网掩码为255.255.255.0。
ip :IP协议栈相关配置
ip 命令是 iproute2 软件包的一部分,功能比 ifconfig 更强大和灵活。它可以用来管理网络接口、路由、地址、ARP 表等。
查看所有网络接口的 IP 地址:这会显示所有网络接口的 IP 地址信息。
$ ip addr show 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 inet 127.0.0.1/8 scope host lo valid_lft forever preferred_lft forever inet6 ::1/128 scope host valid_lft forever preferred_lft forever 2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000 link/ether 00:15:5d:d2:46:21 brd ff:ff:ff:ff:ff:ff inet 172.17.156.11/20 brd 172.17.159.255 scope global eth0 valid_lft forever preferred_lft forever inet6 fe80::215:5dff:fed2:4621/64 scope link valid_lft forever preferred_lft forever启用或禁用网络接口:
ip link set eth0 up ip link set eth0 downup启用eth0接口,down禁用eth0接口。查看路由表:
ip route show default via 172.17.144.1 dev eth0 proto kernel 172.17.144.0/20 dev eth0 proto kernel scope link src 172.17.156.11这会显示当前系统的路由表信息。
添加或删除 IP 地址:
ip addr add 192.168.1.100/24 dev eth0 ip addr del 192.168.1.100/24 dev eth0这会在
eth0接口上添加或删除 IP 地址192.168.1.100,子网掩码为255.255.255.0。查看网络接口的链路状态:
ip link show 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP mode DEFAULT group default qlen 1000 link/ether 00:15:5d:d2:46:21 brd ff:ff:ff:ff:ff:ff这会显示所有网络接口的链路状态(如是否启用、MAC 地址等)。
ipconfig :Windows 命令
排查网络连接问题:
使用
ipconfig查看 IP 地址、网关和 DNS 是否正确。使用
ipconfig /release和ipconfig /renew重新获取 IP 地址。
刷新 DNS 缓存:
当域名解析出现问题时,使用
ipconfig /flushdns清除缓存。
查看网络配置:
使用
ipconfig /all查看详细的网络配置信息。
检查网络接口状态:
确认网络接口是否已启用并获取到正确的 IP 地址。
防火墙相关配置
可以用 iptables 、 nft 、 firewalld 等命令实现。
番外:查询公网 ipv4
访问 https://ifconfig.me 查询,对应命令就是:
curl ifconfig.me2.3 网络性能监控
netstat 显示网络连接、路由表、接口统计信息等。(已逐渐被 ss 替代)
示例:查询监听端口号 35279 运行的进程
$ sudo netstat -tulnp | grep 35279 Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name tcp 0 0 0.0.0.0:35279 0.0.0.0:* LISTEN 258/1panel-t:显示 TCP 协议的连接和监听端口。
TCP 是一种面向连接的协议,常用于 HTTP、HTTPS、SSH、FTP 等。
-u:显示 UDP 协议的连接和监听端口。
UDP 是一种无连接的协议,常用于 DNS、DHCP、视频流等。
-l:显示 监听(LISTEN) 状态的端口。
这些端口正在等待来自客户端的连接请求。
-n:以 数字形式 显示地址和端口号,而不是尝试解析主机名、服务名等。
例如,显示
127.0.0.1:80而不是localhost:http。
-p:显示与每个连接或监听端口关联的 进程 ID(PID) 和 进程名称。
需要
sudo权限才能查看其他用户的进程信息。
ss 用于显示套接字的状态,功能更强大且效率更高,可以替代
netstat。示例:
$ sudo ss -tulnp | grep 35279 Netid State Recv-Q Send-Q Local Address:Port Peer Address:Port Process tcp LISTEN 0 4096 0.0.0.0:35279 0.0.0.0:* users:(("1panel",pid=258,fd=29))lsof 全称是 List Open Files,它可以显示当前系统中所有打开的文件(包括网络连接、设备、管道等)以及使用这些文件的进程。
示例:
$ sudo lsof -i :35279 COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME 1panel 258 root 29u IPv4 26827 0t0 TCP *:35279 (LISTEN)sar命令当前网络的吞吐率和 PPS。笔者电脑里没有默认安装。
2.4 网络故障排查
ping 检查网络连接是否正常,发送ICMP请求数据包并等待响应。
示例:
ping google.com ping -c 4 192.168.1.1traceroute 显示到达目的地的路径以及每个节点的响应时间。
示例:
# -n 代表不查主机名 -T 使用 TCP 而非 ICMP 连接 $ sudo traceroute -n -T www.baidu.com traceroute to www.baidu.com (39.156.66.18), 30 hops max, 60 byte packets 1 172.17.144.1 0.401 ms 0.391 ms 0.387 ms 2 * * * 3 * * 172.25.254.1 3.921 ms 4 * * * 5 * * * 6 * * * 7 * * * 8 * * * 9 * * * 10 * * 39.156.27.1 20.648 ms 11 * * 39.156.27.1 20.638 ms 12 * * * 13 * * * 14 * * * 15 * * * 16 * 39.156.66.18 23.966 ms 21.709 msnslookup 查询DNS记录,检查DNS解析问题。
示例:
nslookup google.comdig 另一个DNS查询工具,功能比
nslookup更强大。示例:
dig google.comroute 查看和设置路由表。可以帮助排查路由问题。
示例:
route -ntcpdump 捕获和分析网络数据包,可以用于排查网络故障。
示例:
sudo tcpdump -i eth0 sudo tcpdump -i eth0 port 80mtr 是
traceroute和ping的结合(My Traceroute),提供了实时更新的网络故障排查信息。示例:
mtr google.com
3. 系统与网络编程
计算机系统与网络系统的关系可以通过以下几个方面来理解:
计算机系统:计算机系统通常指的是硬件、操作系统以及各种应用程序的结合。硬件部分包括CPU、内存、硬盘、显示器、输入设备等,操作系统提供资源管理与调度服务,应用程序执行具体的任务。
网络系统:网络系统是指计算机与其他计算机或设备通过各种通信媒介和协议进行信息交换的系统。它包括了物理层、数据链路层、网络层、传输层等网络协议栈的设计与实现,通常通过网络接口卡、路由器等硬件设备与计算机系统连接。
关系:
硬件支持:计算机系统的硬件需要通过网络接口卡(NIC)与外部的网络进行通信。
操作系统支持:操作系统提供对网络硬件的管理以及网络协议的实现,允许应用程序通过系统调用来访问网络服务。
网络协议:计算机系统与网络系统之间的通信依赖于网络协议,例如TCP/IP协议栈。操作系统通过协议栈处理网络数据包的发送和接收,并将数据交给上层应用。
总的来说,计算机系统为网络系统提供了运行的硬件和操作系统基础,而网络系统通过网络协议和硬件实现计算机间的通信和数据交换。
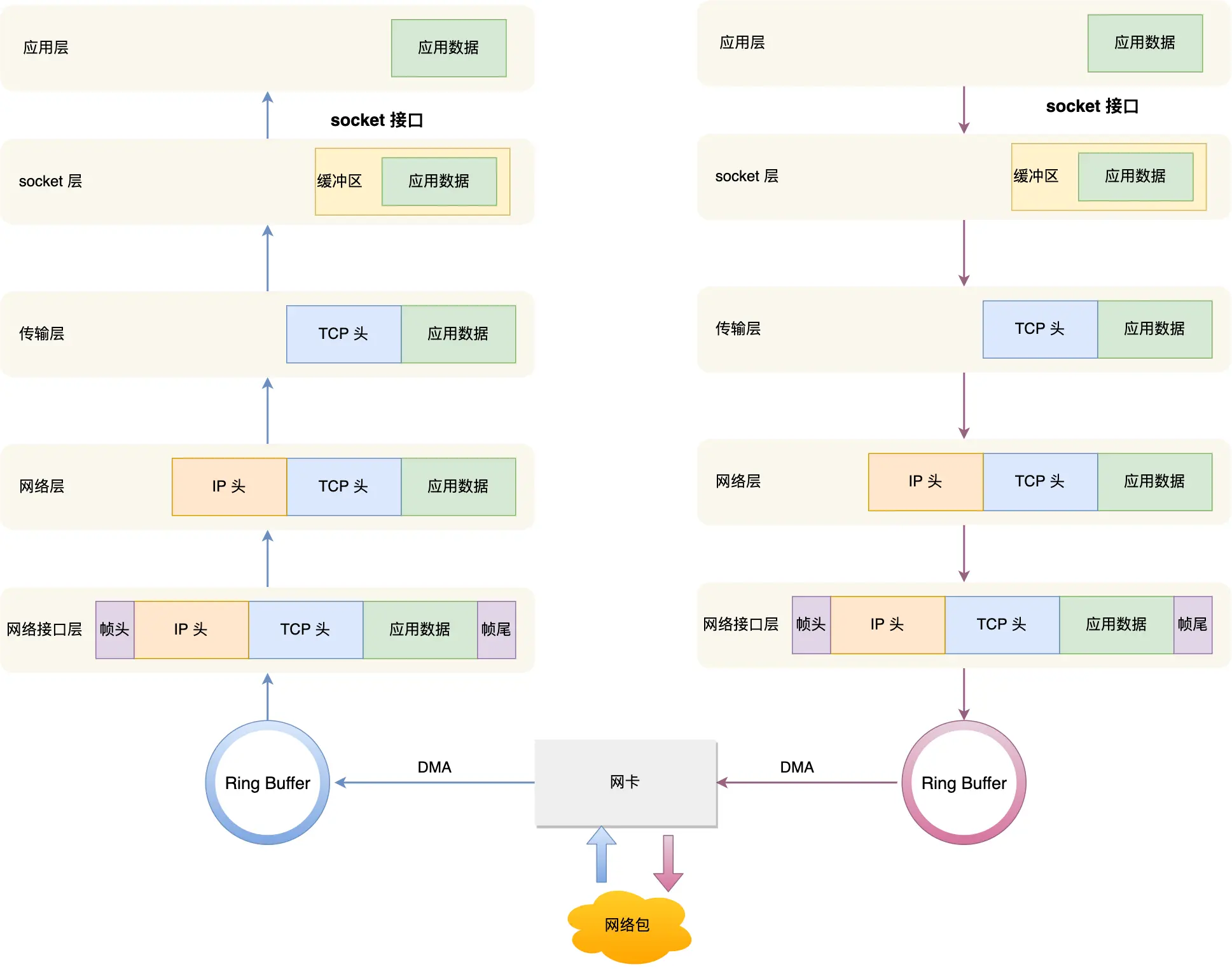
以下将从自底向上的整体顺序进行讲述。
3.1 网络系统与计算机组成
数据链路层的网络包只是存放在内存中的一串二进制数字信息,没有办法直接发送给对方。因此,我们需要将数字信息转换为电信号,才能在物理层网线上传输,也就是说,这才是真正的数据发送过程。
负责执行这一操作的是网卡。
3.1.1 网卡是 I/O 设备
网卡是计算机里的一个硬件,专门负责接收和发送网络包,通过总线(如PCIe)与计算机的主板连接,并通过中断机制或DMA(直接内存访问)与CPU和内存进行数据交换。
比如网卡接收到一个网络包后,会通过 DMA 技术,将网络包写入到指定的内存地址,也就是写入到 Ring Buffer。
3.1.2 网卡驱动程序
控制网卡最直接的方式是靠网卡驱动程序。这里是数据链路层的工作。
网卡驱动获取网络包之后,会将其复制到网卡内的缓存区中,接着会在其开头加上报头和起始帧分界符,在末尾加上用于检测错误的帧校验序列。
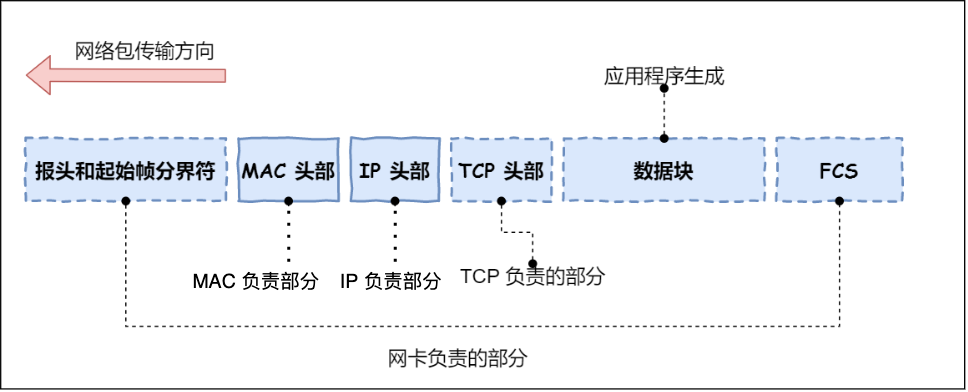
起始帧分界符是一个用来表示包起始位置的标记
末尾的
FCS(帧校验序列)用来检查包传输过程是否有损坏
最后网卡会将包转为电信号,通过网线发送出去。
3.2 操作系统内核的网络协议栈
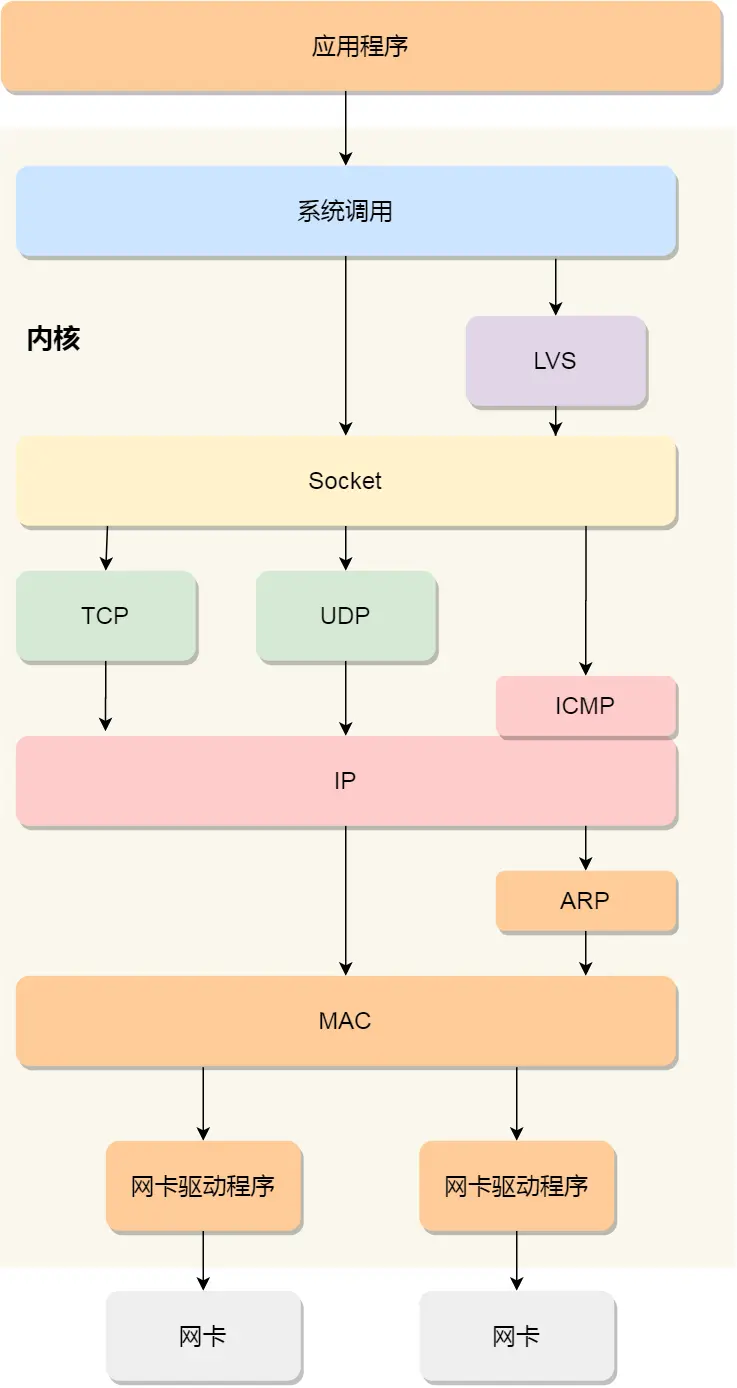
3.2.1 网卡与内核的收发机制
首先,Socket 是一个文件。
每一个进程都有一个数据结构 task_struct,该结构体里有一个指向「文件描述符数组」的成员指针。该数组里列出这个进程打开的所有文件的文件描述符。数组的下标是文件描述符,是一个整数,而数组的内容是一个指针,指向内核中所有打开的文件的列表,也就是说内核可以通过文件描述符找到对应打开的文件。
然后每个文件都有一个 inode,Socket 文件的 inode 指向了内核中的 Socket 结构,在这个结构体里有两个队列,分别是发送队列和接收队列,这个两个队列里面保存的是一个个 struct sk_buff,用链表的组织形式串起来。
sk_buff 可以表示各个层的数据包,在应用层数据包叫 data,在 TCP 层我们称为 segment,在 IP 层我们叫 packet,在数据链路层称为 frame。
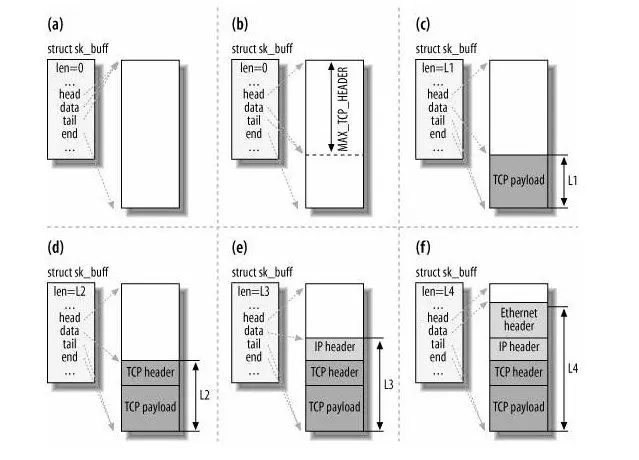
为了在层级之间传递数据时,不发生拷贝,只用 sk_buff 一个结构体来描述所有的网络包,那它是如何做到的呢?是通过调整 sk_buff 中 data 的指针,比如:
当接收报文时,从网卡驱动开始,通过协议栈层层往上传送数据报,通过增加 skb->data 的值,来逐步剥离协议首部。
当要发送报文时,创建 sk_buff 结构体,数据缓存区的头部预留足够的空间,用来填充各层首部,在经过各下层协议时,通过减少 skb->data 的值来增加协议首部。
你可以从下面这张图看到,当发送报文时,data 指针的移动过程。
1. 发送流程
应用程序准备数据:
应用程序通过系统调用(如
send())将数据传递给内核。内核逐层包装,将数据封装成网络包(
sk_buff结构体),并将其放入发送队列。
触发软中断:
当发送队列中有新的网络包时,内核会触发软中断,通知网卡驱动程序有数据需要发送。
驱动程序处理:
网卡驱动程序从发送队列中读取
sk_buff。将
sk_buff挂载到网卡的 RingBuffer(环形缓冲区) 中,通知网卡有新的数据需要发送。将
sk_buff的数据映射到网卡可访问的 DMA(直接内存访问)区域。以便网卡可以直接读取数据。
网卡发送数据:
网卡从 DMA 区域读取数据,并通过物理介质(如网线)将数据发送出去。
发送完成后的清理:
数据发送完成后,网卡会触发一个硬中断,通知 CPU 数据已发送。
硬中断处理程序释放
sk_buff内存并清理 RingBuffer。当收到 TCP 报文的 ACK 应答 时,传输层会释放原始的
sk_buff。
2. 接收流程
数据到达网卡:
网络包通过物理介质到达网卡。
网卡通过 DMA 技术,将网络包直接写入到指定的内存地址(通常是 RingBuffer)。
触发硬中断:
网卡向 CPU 发起硬中断,通知 CPU 有新的网络包到达。
CPU 根据中断表,调用已注册的硬中断处理函数。
硬中断处理函数的工作:
暂时屏蔽中断:告诉网卡,下次收到数据包时直接写内存即可,不要再通知 CPU,避免频繁中断。
发起软中断:通知内核有新的网络包需要处理。
恢复中断:重新启用中断。
软中断处理:
内核中的 ksoftirqd 线程 负责处理软中断。
ksoftirqd 线程从 RingBuffer 中获取数据帧,封装为
sk_buff。将
sk_buff交给网络协议栈进行逐层处理(如链路层、网络层、传输层等)。
数据传递给应用程序:
网络协议栈处理完成后,将数据传递给目标应用程序(如通过
recv()系统调用)。
关键点总结
发送流程:
应用程序 → 内核 → 网络协议栈 → 发送队列 → 软中断 → 驱动程序 → RingBuffer → DMA → 网卡发送。
发送完成后,通过硬中断清理内存。
接收流程:
网卡接收数据 → DMA 写入内存 → 硬中断 → 软中断 → ksoftirqd 线程 → 网络协议栈 → 应用程序。
中断的作用:
硬中断:通知 CPU 有紧急事件(如数据到达或发送完成)。
软中断:处理耗时任务(如网络包的处理),避免硬中断占用过多 CPU 时间。
DMA 的作用:
允许网卡直接访问内存,减少 CPU 的负担,提高数据传输效率。网卡通过 DMA 直接从内存中读取数据并发送出去。
RingBuffer:
用于缓存待发送或接收的网络包,是网卡和内核之间的桥梁。网卡通过 RingBuffer 知道有哪些数据需要发送。
其他需要注意的点:
访问
127.0.0.1本地 IPv4 回环不经过物理网卡,当程序尝试访问 127.0.0.1 时,操作系统会将该地址识别为本地回环地址,并在本地网络协议栈中进行处理,而不需要通过物理网卡发送数据到外部网络。
3.2.2 网络系统的系统调用
系统调用是操作系统提供给应用程序的接口,应用程序通过系统调用来请求操作系统提供的服务。在网络编程中,常用的系统调用包括:
socket(): 创建一个新的套接字(socket),用于网络通信。
bind(): 将套接字与本地地址和端口绑定。
listen(): 使套接字进入监听状态,等待客户端连接。
accept(): 接受客户端的连接请求,返回一个新的套接字用于与客户端通信。
connect(): 客户端使用该函数连接到服务器。
send() / recv(): 发送和接收数据。
close(): 关闭套接字,释放资源。
这些系统调用是网络编程的基础,通过它们可以实现网络通信。
3.3 Socket 编程
Socket编程是一种通过套接字(Socket)进行网络通信的技术。在网络系统中,Socket是操作系统为进程间通信提供的接口。Socket编程主要分为两种类型:
面向连接的通信:通常使用TCP协议。客户端和服务器之间需要通过Socket建立连接,然后进行数据交换,最后断开连接。
无连接的通信:通常使用UDP协议。客户端和服务器之间没有持久的连接,数据是通过简单的包进行传输。
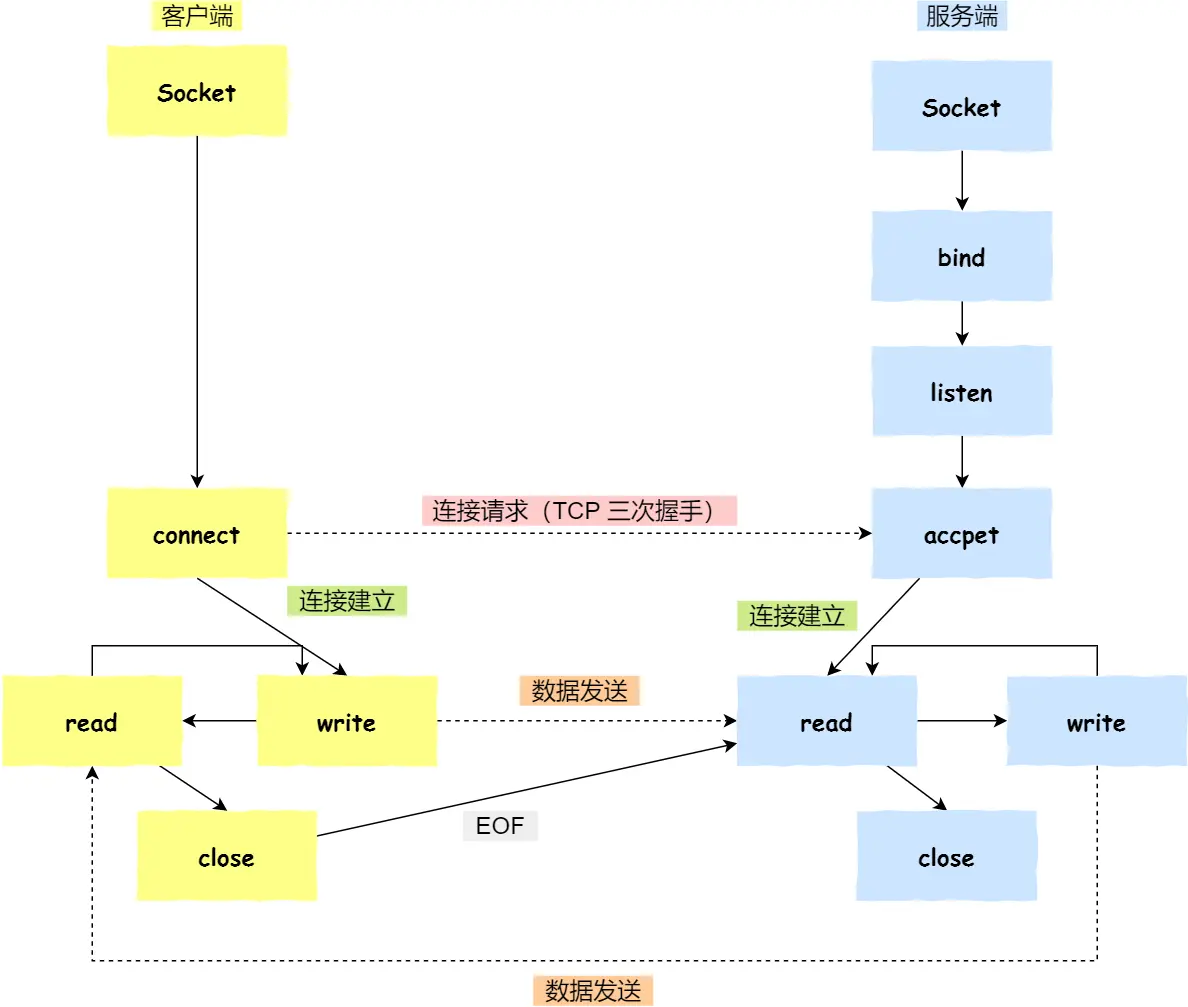
1. 基本的TCP套接字编程步骤
创建Socket:使用
socket()函数创建一个套接字。绑定端口(服务器端):使用
bind()函数将套接字与本地IP地址和端口号绑定。绑定端口的目的:当内核收到 TCP 报文,通过 TCP 头里面的端口号,来找到我们的应用程序,然后把数据传递给我们。
绑定 IP 地址的目的:一台机器是可以有多个网卡的,每个网卡都有对应的 IP 地址,当绑定一个网卡时,内核在收到该网卡上的包,才会发给我们;
监听端口(服务器端):使用
listen()函数使套接字处于监听状态,等待客户端连接。可以通过
netstat命令查看对应的端口号是否有被监听。该函数有个参数
backlog,可以控制下面的全连接队列(accept队列)的大小。
接受连接(服务器端):使用
accept()函数接受客户端的连接请求。如果没有客户端连接,则会阻塞等待客户端连接的到来。发起连接(客户端):客户端在创建好 Socket 后,调用
connect()函数发起连接,该函数的参数要指明服务端的 IP 地址和端口号,然后万众期待的 TCP 三次握手就开始了。在 TCP 连接的过程中,服务器的内核实际上为每个 Socket 维护了两个队列:
一个是「还没完全建立」连接的队列,称为 TCP 半连接队列,这个队列都是没有完成三次握手的连接,此时服务端处于
syn_rcvd的状态;一个是「已经建立」连接的队列,称为 TCP 全连接队列,这个队列都是完成了三次握手的连接,此时服务端处于
established状态;
当 TCP 全连接队列不为空后,服务端的
accept()函数,就会从内核中的 TCP 全连接队列里拿出一个已经完成连接的 Socket 返回应用程序,后续数据传输都用这个 Socket。注意,监听的 Socket 和真正用来传数据的 Socket 是两个:一个叫作监听 Socket;
一个叫作已连接 Socket;
数据交换:通过
send()和recv()函数(系统调用是read、write)进行数据发送和接收。关闭连接:通过
close()函数关闭套接字,断开连接。
2. 示例代码(TCP服务器端)
这里需要非常熟练,要明确每一行都是什么意思,最好能独立写出。
import socket
server_socket = socket.socket(
socket.AF_INET, # 使用IPv4
socket.SOCK_STREAM # 使用TCP协议
)
# '0.0.0.0' 表示服务器将监听所有可用的网络接口
# 服务器最多允许5个连接请求在队列中等待处理
server_socket.bind(('0.0.0.0', 12345))
server_socket.listen(5)
print("Server is listening...")
# 方法会阻塞,直到有客户端连接
client_socket, addr = server_socket.accept()
print(f"Connection from {addr}")
# 从客户端接收最多1024字节的数据
data = client_socket.recv(1024)
print(f"Received: {data.decode()}")
# 向客户端发送数据
client_socket.send(b"Hello from server") # 注意这个 b 相当于把字符串变成字节类型
client_socket.close() # 与当前客户端的通信结束
server_socket.close() # 停止接受新的客户端连接
3. 示例代码(TCP客户端端)
import socket
client_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
client_socket.connect(('127.0.0.1', 12345))
client_socket.send(b"Hello from client")
data = client_socket.recv(1024)
print(f"Received: {data.decode()}")
client_socket.close()上述代码展示了一个简单的TCP客户端和服务器应用,客户端向服务器发送消息,服务器接收并回应消息。
3.4 网络编程中常见的错误
这里的各种错误可能在应用程序、操作系统内核(协议栈)、网络设备、物理层等层次发生,但最终都会通过系统调用,在应用程序上抛出错误。
不同的应用程序(如 Java、Python、JavaScript、浏览器、ApiPost等)抛出的错误大多大同小异,比如连接超时,浏览器的错误是 ERR_TIMED_OUT ,而 Java 是抛出一个 SocketTimeoutException 供上层应用进行异常处理。
注意,以下均为应用层的错误,以下”原理“中关于 RST、SYN、ACK、TCP 超时重传都是传输层的概念,是发生应用层错误可能的其中一种情况。
3.4.1 Connection Refused 连接拒绝
解释:连接被服务端拒绝。
原理:服务端通常发送 RST 报文拒绝连接,客户端收到响应。
触发条件:服务端未启动、端口未监听、防火墙阻止等。
抓包表现:(一般)客户端发送 SYN,服务端返回 RST。
错误码:
ECONNREFUSED
通常发生在连接建立阶段(三次握手)。
有时候不会发送 RST 报文,而是操作系统根据具体情况直接反馈出一个 ECONNREFUSED 错误。
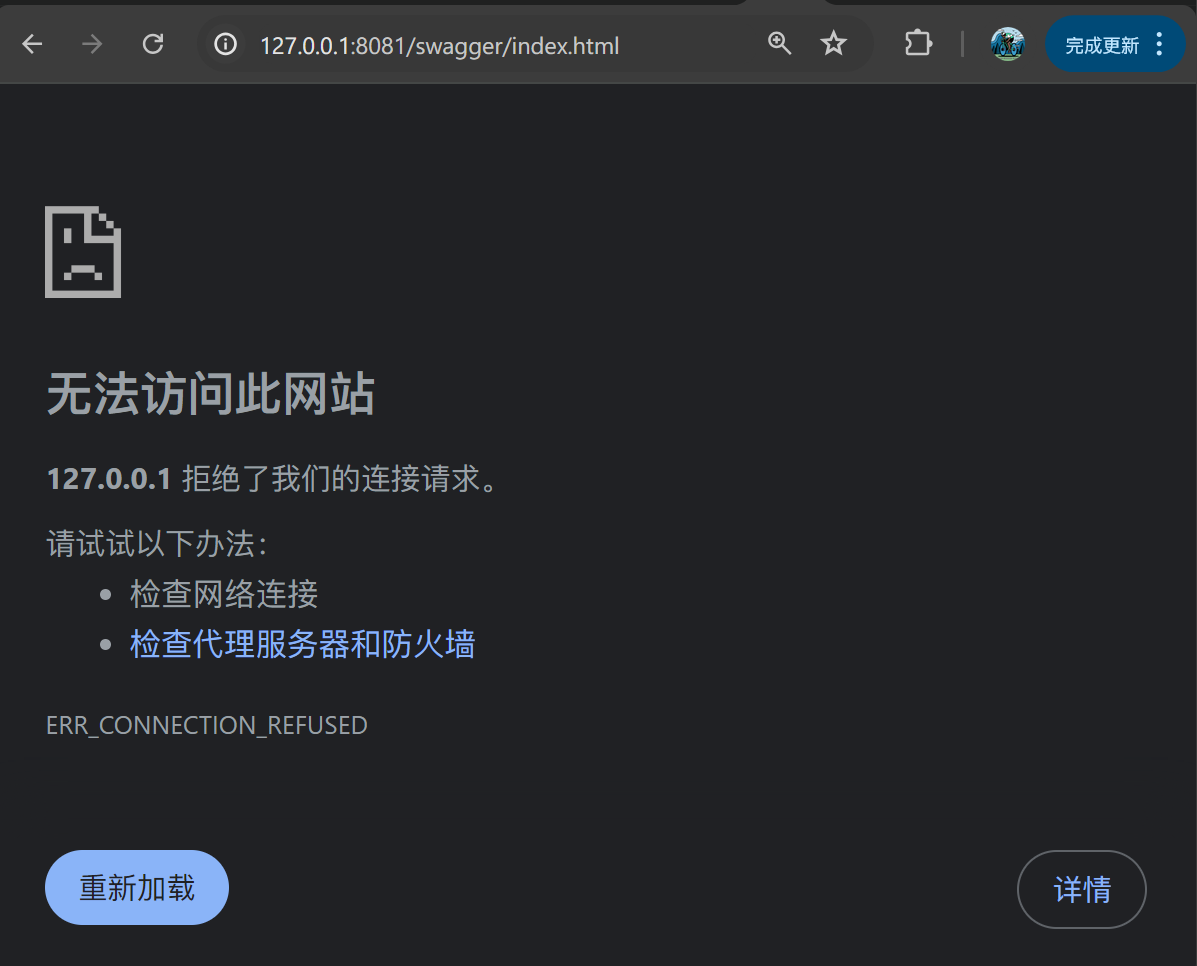
如访问一个未监听的端口,这里是一个没有启动的Web服务,浏览器会报以下错误:
如果 Springboot 程序的 MySQL 服务没启动或者端口配错了,也会报如下异常:
Caused by: java.net.ConnectException: Connection refused: connect
at java.net.DualStackPlainSocketImpl.waitForConnect(Native Method) ~[na:1.8.0_401]
at java.net.DualStackPlainSocketImpl.socketConnect(DualStackPlainSocketImpl.java:81) ~[na:1.8.0_401]
at java.net.AbstractPlainSocketImpl.doConnect(AbstractPlainSocketImpl.java:476) ~[na:1.8.0_401]
at java.net.AbstractPlainSocketImpl.connectToAddress(AbstractPlainSocketImpl.java:218) ~[na:1.8.0_401]
at java.net.AbstractPlainSocketImpl.connect(AbstractPlainSocketImpl.java:200) ~[na:1.8.0_401]
3.4.2 Socket Timeout 连接或请求超时
解释:连接或请求超时。
原理:发送方发送数据后,未收到 ACK 或数据,触发多次超时重传。
触发条件:网络延迟高、服务端处理慢、超时设置短。
抓包表现:数据包重传,未收到 ACK。
错误码:
ETIMEDOUT
通常发生在连接建立后,等待数据或响应时(Read Time Out);
也可以是未能在指定时间内完成 TCP 三次握手等情况(回应 SYN 超时报Connection Time Out,回应最后的ACK报 Read Time Out)
比如我不小心把 ip 地址输错,ip 地址不可达,(这里 traceroute 会报 * * * )会出现如下错误:
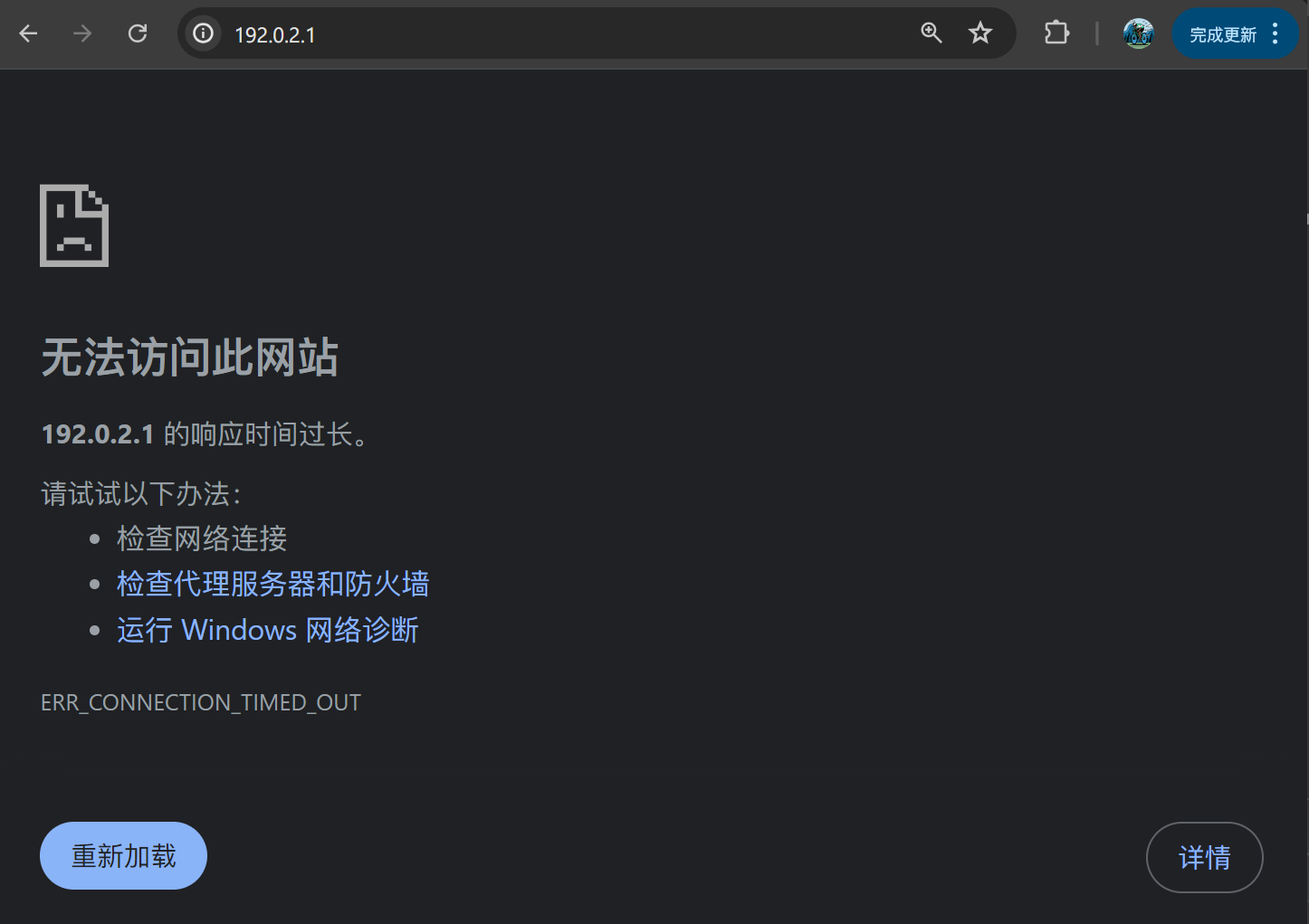
下面的图懂的都懂,也是这个原理。
3.4.3 Connection Reset 连接强制关闭
解释:连接被对端强制关闭。
原理:对端发送 RST 报文强制关闭连接。
触发条件:服务端崩溃、资源耗尽、非法数据。
抓包表现:对端发送 RST 报文。
错误码:
ECONNRESET
发生在连接建立后,因异常情况强制关闭连接。
比如我给一个 Springboot 程序发 http 请求,而接口处理时我手动 kill 了这个进程,则 http 请求的响应为:
There was an error accessing to URL: http://localhost:8081/login/signIn
Connection refused: connectWireShark 抓包如下:

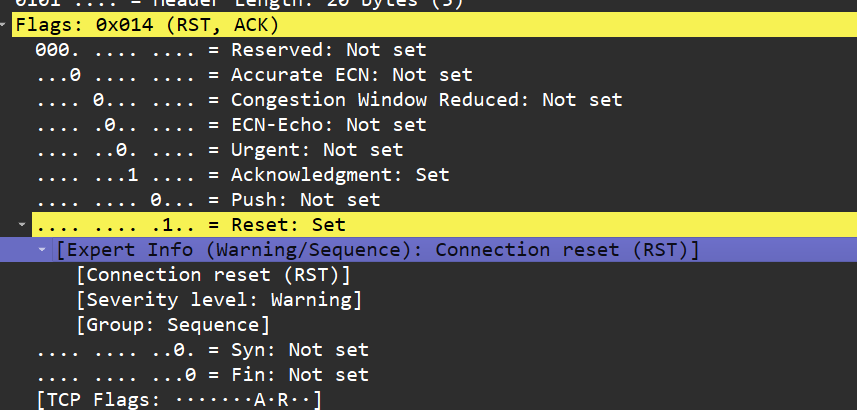
如果是线程崩溃但进程仍在运行:客户端会收到 500 Internal Server Error 或其他自定义错误响应。
3.5 扩展:RIO包
如果用 C 语言进行套接字编程,实际上在读写时推荐用 RIO 包。(不用 Unix 的系统调用 I/O,也不要用 C 语言的标准流式 I/O)
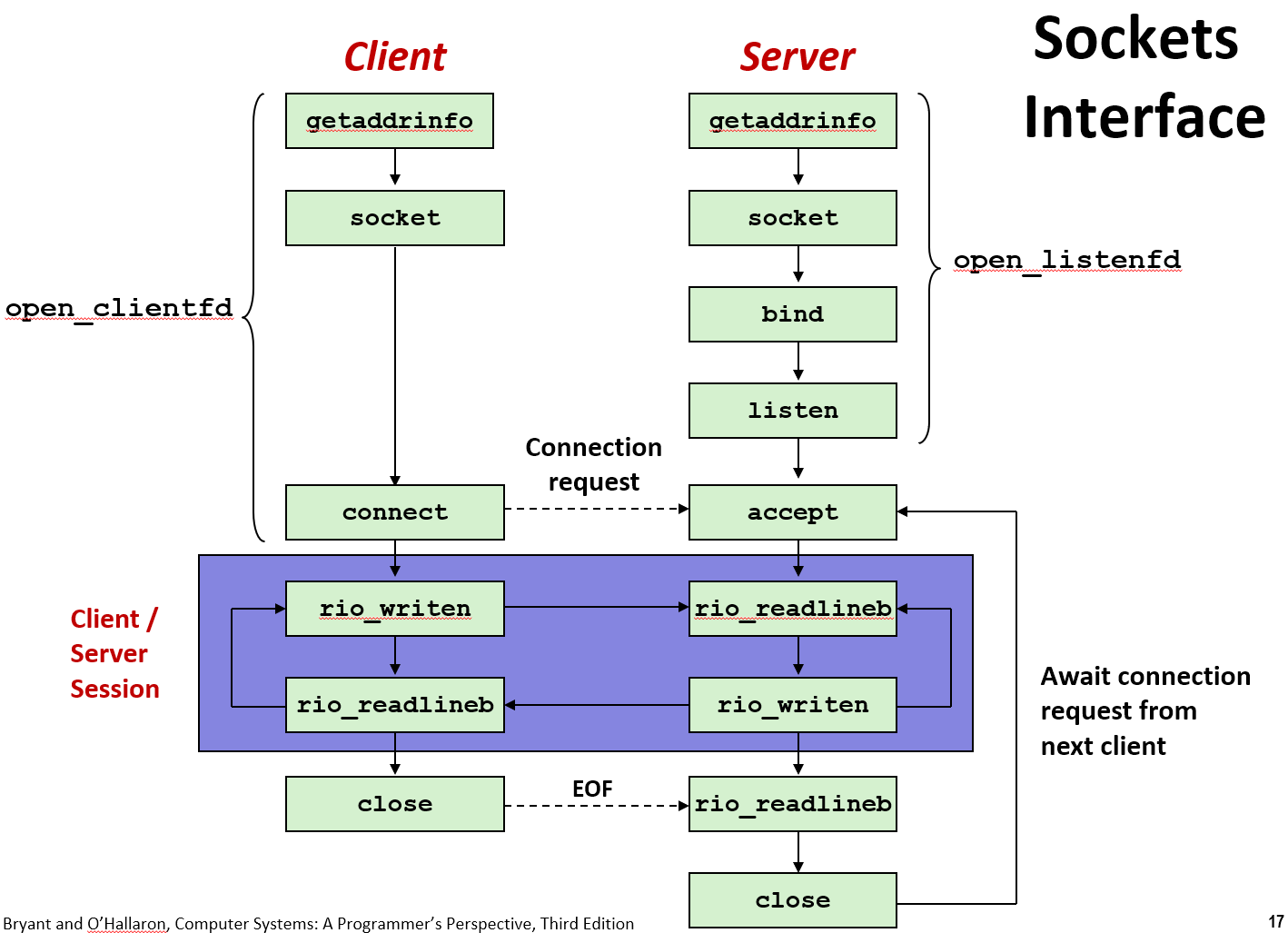
3.5.1 不足值
Socket 是文件,因此有其文件描述符 fd,我们也可以用 read 进行读取:

其中可能会发生一种情况:实际读取的字节数(nbytes的值)要小于要读取的字节数(sizeof(buf));
在读写网络套接字时,会发生这种情况。
最好的做法是始终允许不足值。
3.5.2 无缓冲 RIO


/*
* rio_readn – 健壮地读取 n 个字节(非缓冲)
*/
ssize_t rio_readn(int fd, void *usrbuf, size_t n)
{
size_t nleft = n;
ssize_t nread;
char *bufp = usrbuf;
while (nleft > 0) {
if ((nread = read(fd, bufp, nleft)) < 0) {
if (errno == EINTR) // 系统调用被中断
nread = 0; // 此时重新调用 read()
else
return -1; // 由 read() 设置的 errno
}
else if (nread == 0)
break; // EOF
nleft -= nread;
bufp += nread;
}
return (n - nleft); // 返回值 >= 0
}3.5.3 带缓冲 RIO


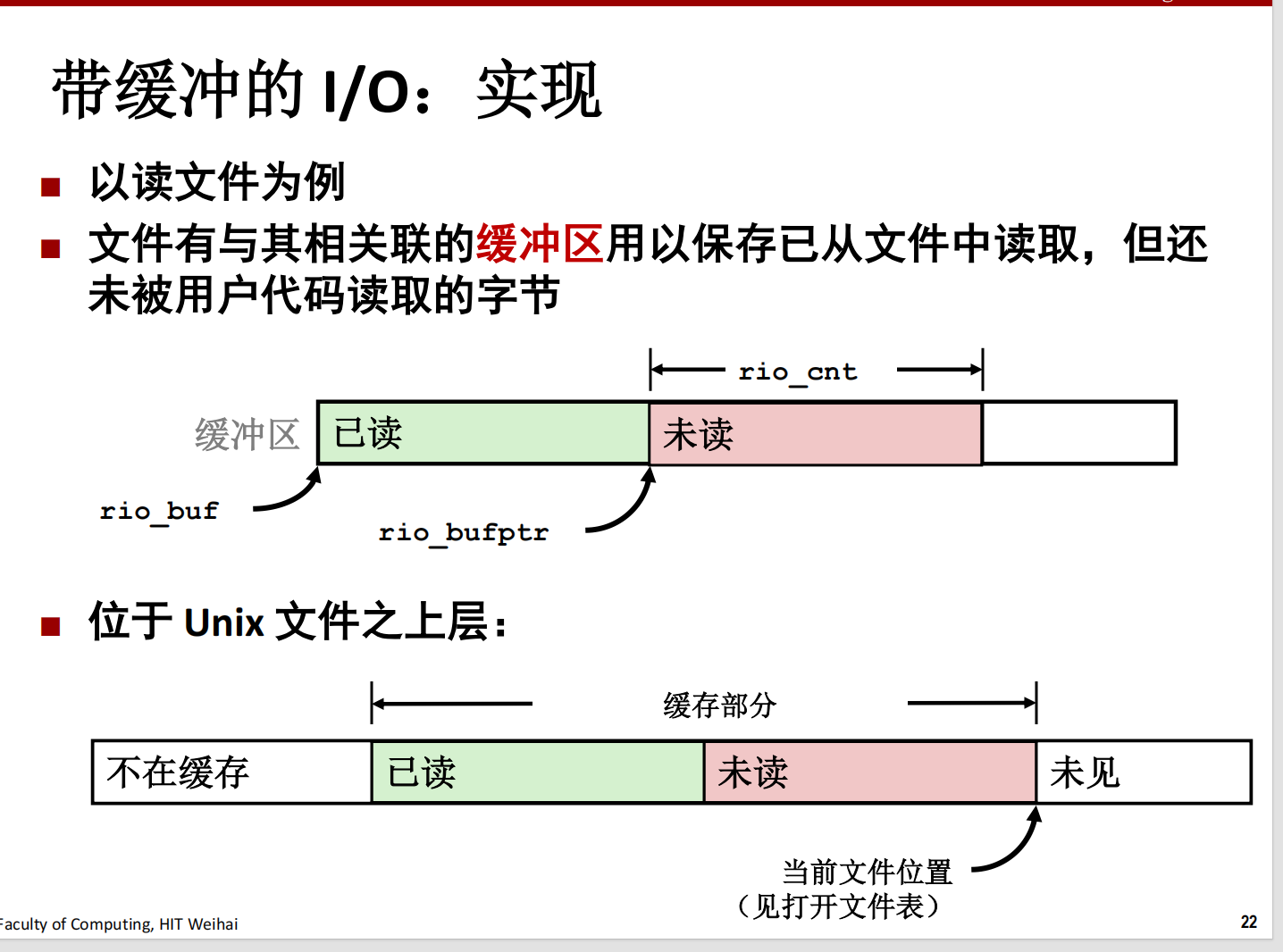
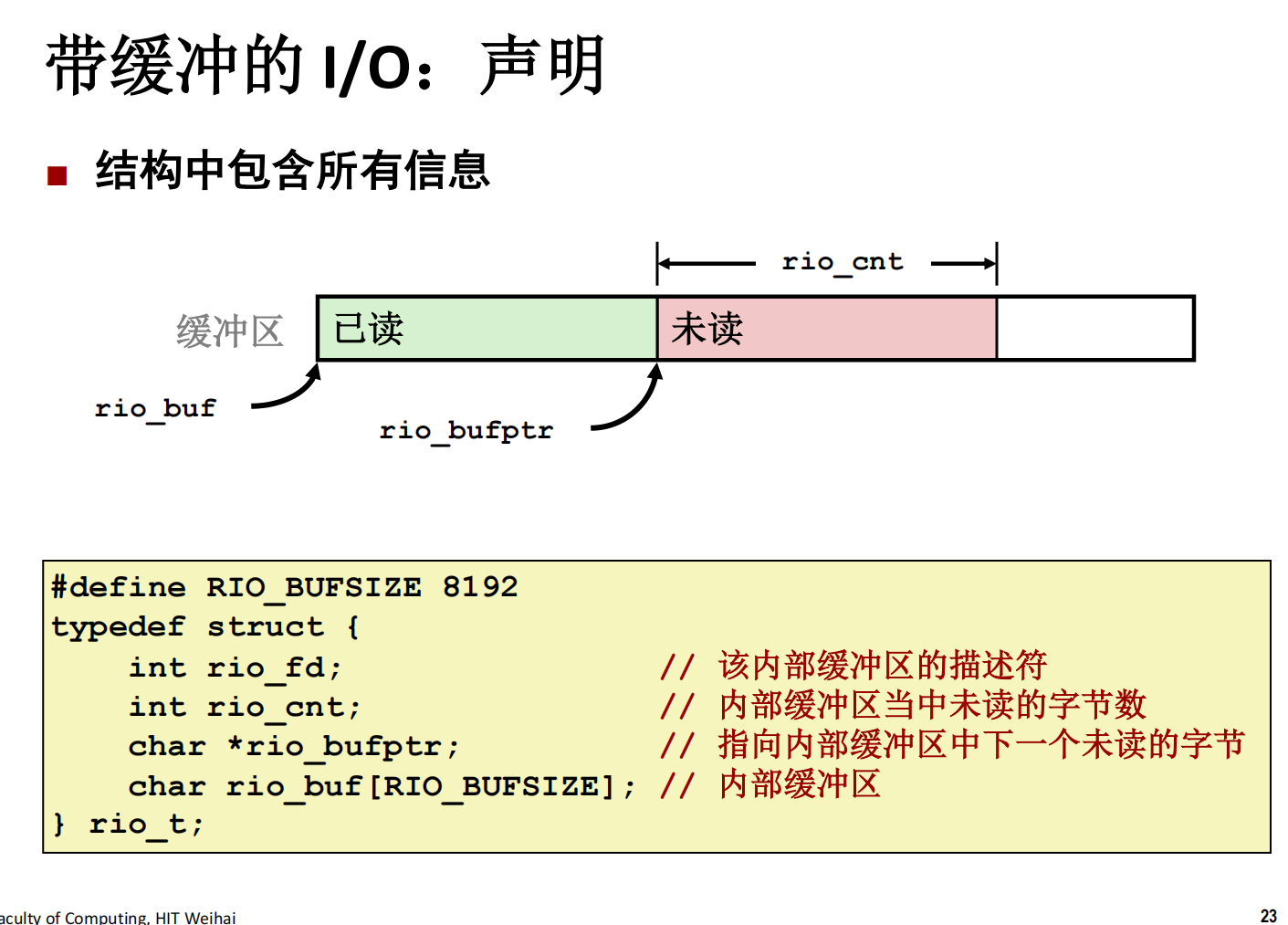
4. 性能优化与设计模式
4.1 TCP 调优与内核参数优化
注重看服务端优化。
4.1.1 TCP 三次握手
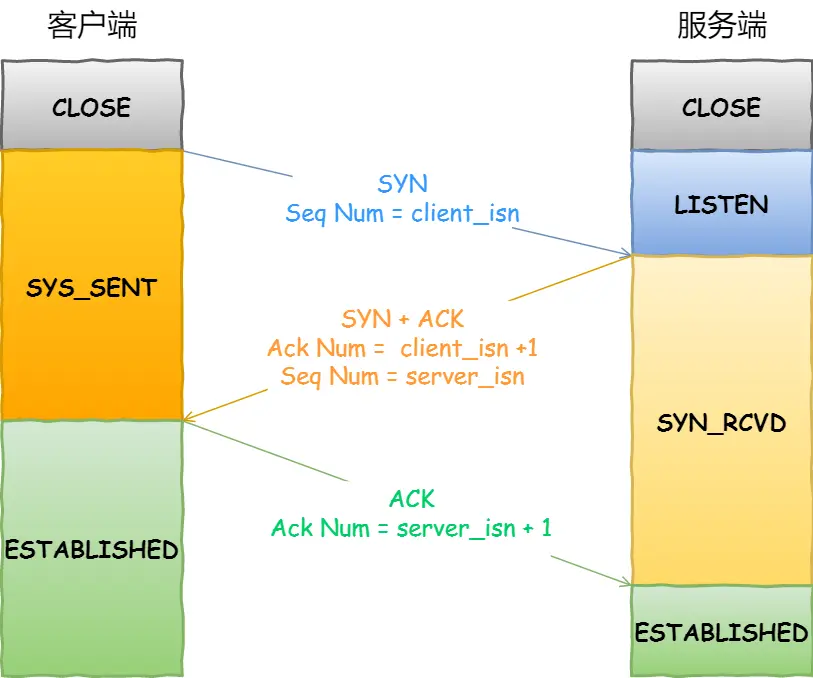
客户端的优化
控制一次握手 SYN 重传的次数:当客户端发起 SYN 包时,可以通过
tcp_syn_retries控制其重传的次数。
服务端的优化
半连接队列:服务端收到客户端的 SYN,会把连接移到半连接队列,等待 SYN+ACK 重传。
当服务端 SYN 半连接队列溢出后,会导致后续连接被丢弃,客户端超时重传,直到 Connect Timed Out。
可以通过
netstat -s观察半连接队列溢出的情况可以通过
tcp_max_syn_backlog参数 + 调整下文 accept 队列长度来调整 SYN 半连接队列的大小。
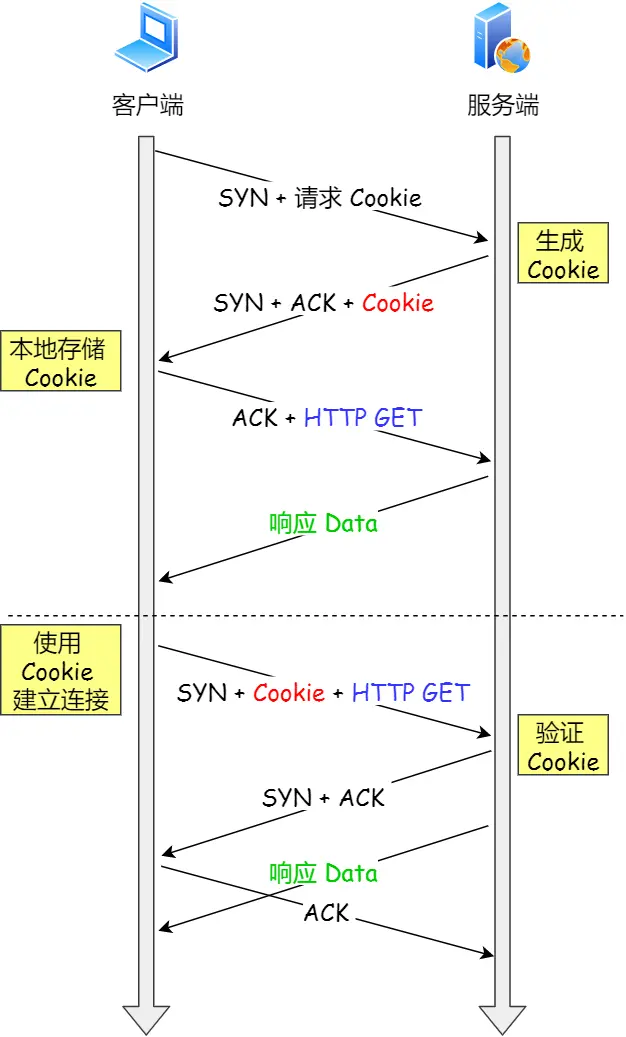
不用半连接队列:如果遭受 SYN 攻击,应把
tcp_syncookies参数设置为 1,表示仅在 SYN 队列满后开启 syncookie 功能,可以在不使用 SYN 半连接队列的情况下成功建立连接。SYN 攻击:SYN攻击中,攻击者发送大量的SYN包,但不回应服务器的SYN-ACK包,导致服务器等待ACK确认而消耗资源,最终可能使服务器无法处理合法的连接请求。解决办法 ①syncookie ②增大半连接队列 ③减少SYNACK重传
控制二次握手 SYNACK 重传次数:服务端回复 SYN+ACK 的重传次数由
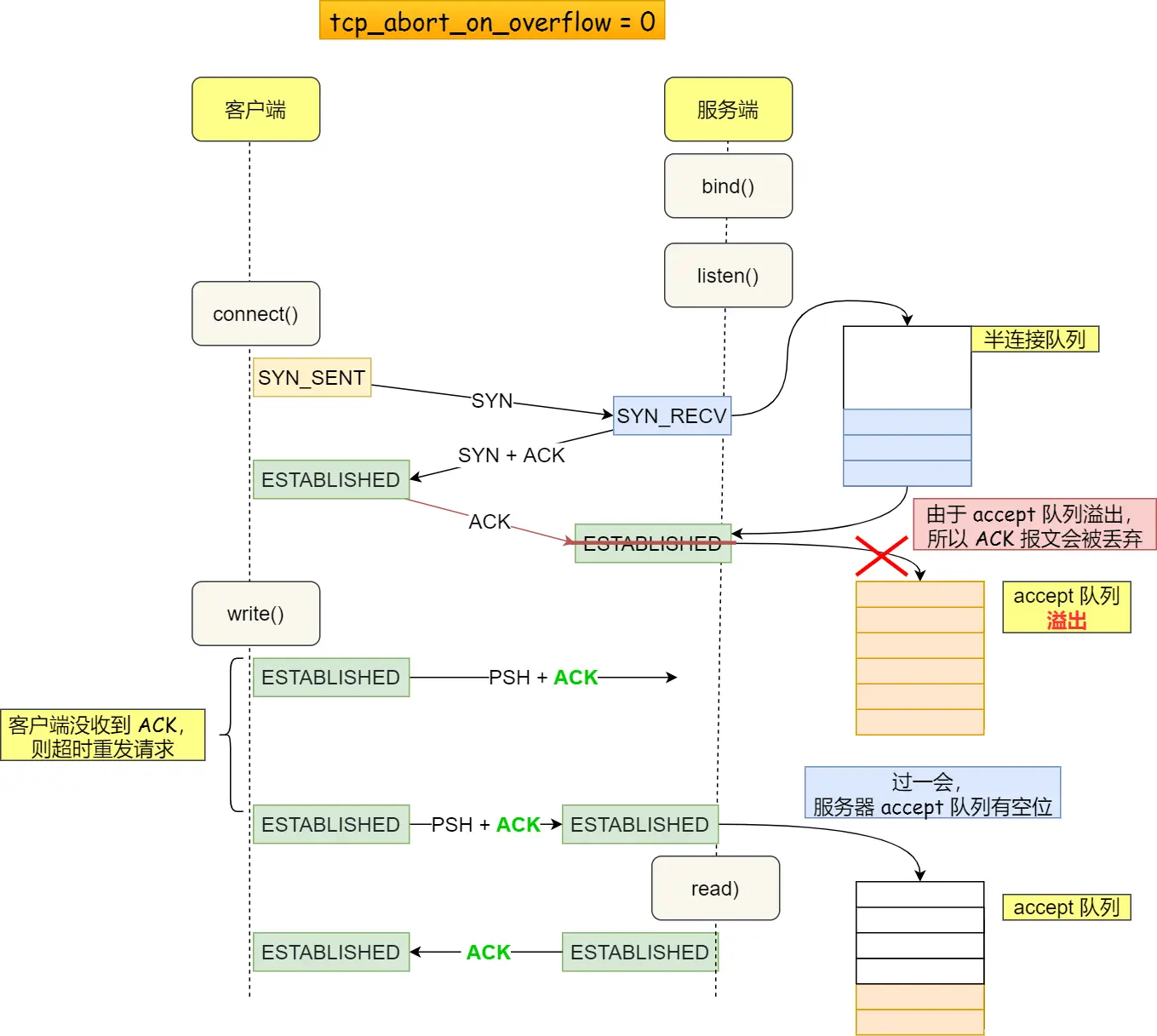
tcp_synack_retries参数控制。全连接队列:服务端收到客户端返回的 ACK,会把连接移入 accpet 队列,等待进行调用 accpet() 函数取出连接。
如果 accept 队列溢出,系统默认丢弃 ACK,触发 ACK 重传,直到 Read Time Out。如果可以把
tcp_abort_on_overflow设置为 1 ,表示用 RST 通知客户端连接建立失败。可以通过
ss -lnt查看服务端进程的 accept 队列长度。可以通过 listen 函数的
backlog应用参数和somaxconn系统参数提高队列大小,accept 队列长度取决于 min(backlog, somaxconn)。
绕过三次握手
TCP Fast Open 功能可以绕过三次握手,使得 HTTP 请求减少了 1 个 RTT 的时间(第一次发 SYN 的时候会带 Cookie),Linux 下可以通过 tcp_fastopen 开启该功能,同时必须保证服务端和客户端同时支持。
4.1.2 TCP 四次挥手
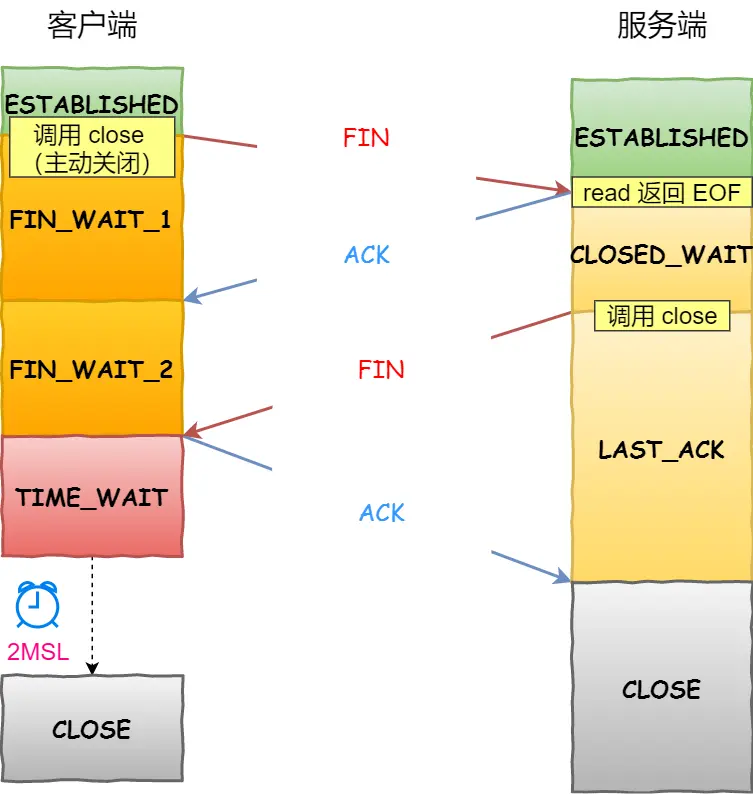
这里一点需要注意是:主动关闭连接的,才有 TIME_WAIT 状态。
主动方的优化
主动方重传 FIN 报文:重传的次数由
tcp_orphan_retries参数决定。收到 ACK 报文后进入 FIN_WAIT2 状态:如果这是 close 函数关闭的连接,那么它就是孤儿连接。如果
tcp_fin_timeout秒内没有收到对方的 FIN 报文,连接就直接关闭。同时,为了应对孤儿连接占用太多的资源,tcp_max_orphans定义了最大孤儿连接的数量,超过时连接就会直接释放。接收到 FIN 报文并返回 ACK 后,TIME_WAIT 状态:
这一状态会持续 1 分钟,2 MSL 。作用:
防止下一次连接收到历史数据,从而导致数据错乱的问题。
等待足够的时间以确保最后的 ACK 能让被动关闭方接收,从而帮助其正常关闭。
MSL 全称是 Maximum Segment Lifetime,它定义了一个报文在网络中的最长生存时间(报文每经过一次路由器的转发,IP 头部的 TTL 字段就会减 1,减到 0 时报文就被丢弃,这就限制了报文的最长存活时间)。
最大数量:为了防止 TIME_WAIT 状态占用太多的资源,
tcp_max_tw_buckets定义了最大数量,超过时连接也会直接释放。端口复用:还可以通过设置
tcp_tw_reuse和tcp_timestamps为 1 ,将 TIME_WAIT 状态的端口复用于作为客户端的新连接,注意该参数只适用于客户端。
4.1.3 TCP 数据传输
目的:能够最大程度地保持并发性,也能让资源充裕时连接传输速度达到最大值。
TCP 可靠性是通过 ACK 确认报文实现的,又依赖滑动窗口提升了发送速度也兼顾了接收方的处理能力。
可是,默认的滑动窗口最大值只有 64 KB,不满足当今的高速网络的要求,要想提升发送速度必须提升滑动窗口的上限,在 Linux 下是通过设置 tcp_window_scaling 为 1 做到的,此时最大值可高达 1GB。主动建立连接的一方在 SYN 报文中发送这个选项;

滑动窗口定义了网络中飞行报文的最大字节数,当它超过带宽时延积时,网络过载,就会发生丢包。而当它小于带宽时延积时,就无法充分利用网络带宽。因此,滑动窗口的设置,必须参考带宽时延积。
内核缓冲区决定了滑动窗口的上限,缓冲区可分为:发送缓冲区 tcp_wmem 和接收缓冲区 tcp_rmem(单位均为字节)。
Linux 会对缓冲区动态调节,我们应该把缓冲区的上限设置为带宽时延积。发送缓冲区的调节功能是自动打开的,而接收缓冲区需要把 tcp_moderate_rcvbuf 设置为 1 来开启。其中,调节的依据是 TCP 内存范围 tcp_mem (单位为页面大小)。
4.2 零拷贝
早期 I/O 操作,内存与磁盘的数据传输的工作都是由 CPU 完成的,而此时 CPU 不能执行其他任务,会特别浪费 CPU 资源。
于是,为了解决这一问题,DMA 技术就出现了,每个 I/O 设备都有自己的 DMA 控制器,通过这个 DMA 控制器,CPU 只需要告诉 DMA 控制器,我们要传输什么数据,从哪里来,到哪里去,就可以放心离开了。后续的实际数据传输工作,都会由 DMA 控制器来完成,CPU 不需要参与数据传输的工作。
传统 IO 的工作方式,从硬盘读取数据,然后再通过网卡向外发送,如果是用户态进程调用系统调用,我们需要进行 4 上下文切换,和 4 次数据拷贝,其中 2 次数据拷贝发生在内存里的缓冲区和对应的硬件设备之间,这个是由 DMA 完成,另外 2 次则发生在内核态和用户态之间,这个数据搬移工作是由 CPU 完成的。
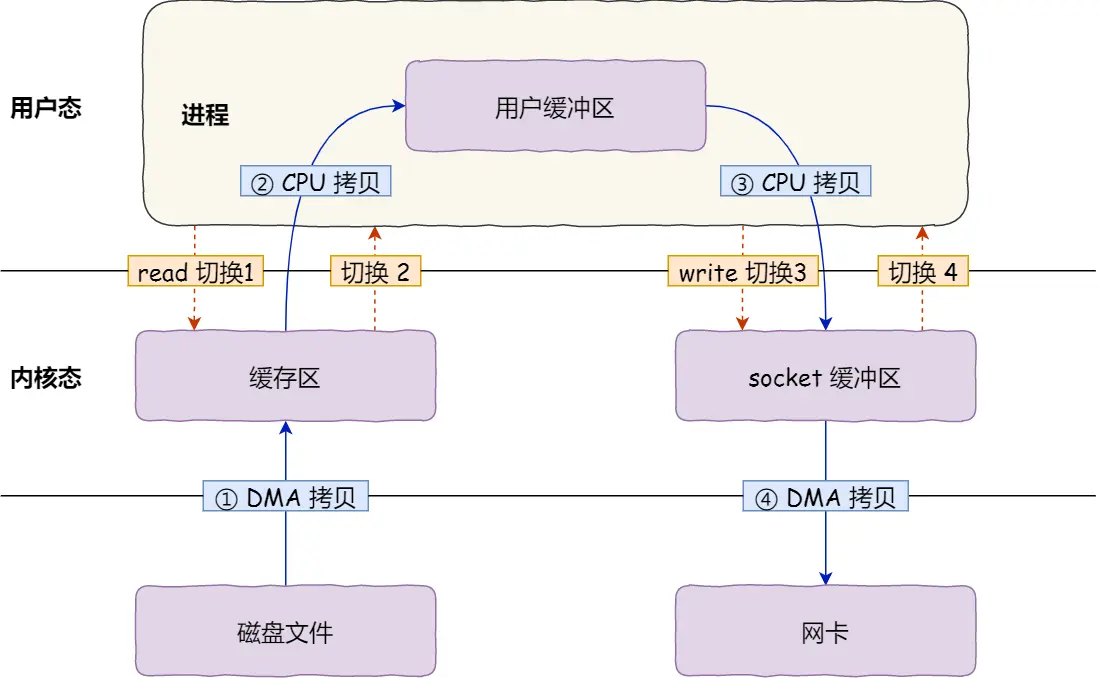
要想提高文件传输的性能,就需要:
减少「用户态与内核态的上下文切换」次数,即减少系统调用次数,现在有 4 次。
减少「内存拷贝」的次数,用户空间我们并不会对数据加工,因此用户缓冲区没有必要存在。现在有 4 次。
4.2.1 sendfile 系统调用
于是,从 Linux 内核 2.4 版本开始,并且网卡支持 SG-DMA 技术的情况下,提供了一个专门发送文件的系统调用函数 sendfile(),函数形式如下:
#include <sys/socket.h>
ssize_t sendfile(int out_fd, int in_fd, off_t *offset, size_t count);它的前两个参数分别是目的端和源端的文件描述符,后面两个参数是源端的偏移量和复制数据的长度,返回值是实际复制数据的长度。
第一步,通过 DMA 将磁盘上的数据拷贝到内核缓冲区里;
第二步,缓冲区描述符和数据长度传到 socket 缓冲区,这样网卡的 SG-DMA 控制器就可以直接将内核缓存中的数据拷贝到网卡的缓冲区里,此过程不需要将数据从操作系统内核缓冲区拷贝到 socket 缓冲区中,这样就减少了一次数据拷贝;
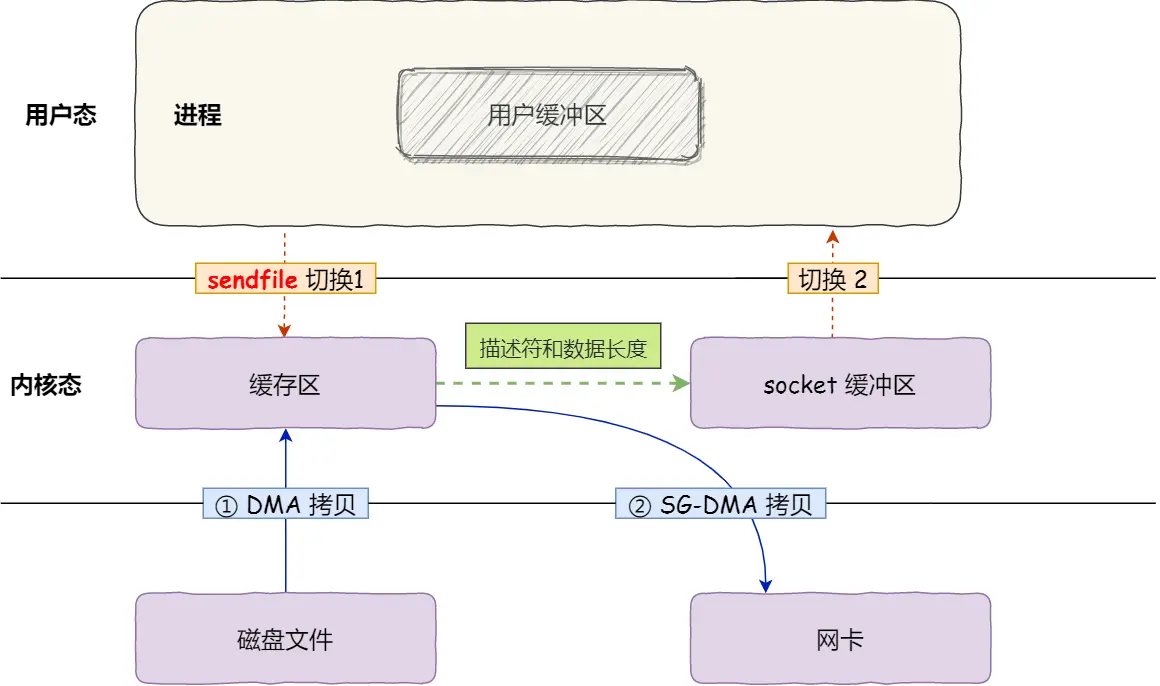
1次系统调用,2次上下文切换,2次拷贝。
这就是所谓的零拷贝(Zero-copy)技术,因为我们没有在内存层面去拷贝数据,也就是说全程没有通过 CPU 来搬运数据,所有的数据都是通过 DMA 来进行传输的。
Kafka 和 Nginx 都有实现零拷贝技术,这将大大提高文件传输的性能。
需要注意的是,零拷贝技术是不允许进程对文件内容作进一步的加工的,比如压缩数据再发送。
4.2.2 缓存区 PageCache
零拷贝技术是基于 PageCache 的,PageCache 会缓存最近访问的数据,提升了访问缓存数据的性能,同时,为了解决机械硬盘寻址慢的问题,它还协助 I/O 调度算法实现了 IO 合并与预读,这也是顺序读比随机读性能好的原因。这些优势,进一步提升了零拷贝的性能。
另外,当传输大文件时,不能使用零拷贝,因为可能由于 PageCache 被大文件占据,而导致「热点」小文件无法利用到 PageCache,并且大文件的缓存命中率不高,这时就需要使用「异步 IO + 直接 IO 」的方式。
4.3 I/O 多路复用
本节内容感觉是最考验操作系统和计网基本功的一集
4.3.1 C10K 问题的解决方案
TCP Socket 调用流程是最简单、最基本的,它基本只能一对一通信,因为使用的是同步阻塞的方式,当服务端在还没处理完一个客户端的网络 I/O 时,或者 读写操作发生阻塞时,其他客户端是无法与服务端连接的。
# server.py
import socket
server_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
server_socket.bind(("127.0.0.1", 8080))
server_socket.listen(5)
print("Server is listening...")
# 不断接受新请求
while True:
client_socket, addr = server_socket.accept()
print(f"Connection from {addr}")
data = client_socket.recv(1024)
print(f"Received: {data.decode()}")
# 向客户端发送数据
client_socket.send("Hello from server".encode())
client_socket.close() # 与当前客户端的通信结束可如果我们服务器只能服务一个客户,那这样就太浪费资源了,于是我们要改进这个网络 I/O 模型,以支持更多的客户端。
服务器的内存只有 2 GB,网卡是千兆的,能支持并发 1 万请求吗?
并发 1 万请求,也就是经典的 C10K 问题 ,C 是 Client 单词首字母缩写,C10K 就是单机同时处理 1 万个请求的问题。
从硬件资源角度看,对于 2GB 内存千兆网卡的服务器,如果每个请求处理占用不到 200KB 的内存和 100Kbit 的网络带宽就可以满足并发 1 万个请求。
不过,要想真正实现 C10K 的服务器,要考虑的地方在于服务器的网络 I/O 模型,效率低的模型,会加重系统开销,从而会离 C10K 的目标越来越远。
比较传统的方式是使用多进程/线程模型,每来一个客户端连接,就分配一个进程/线程,然后后续的读写都在对应的进程/线程,这种方式处理 100 个客户端没问题,但是当客户端增大到 10000 个时,10000 个进程/线程的调度、上下文切换以及它们占用的内存,都会成为瓶颈。
既然为每个请求分配一个进程/线程的方式不合适,那有没有可能只使用一个进程来维护多个 Socket 呢?答案是有的,那就是基于事件的并发技术。
与之前的多线程(进程)不同,基于事件循环的并发是不考虑多线程的,而是在一个线程(进程)上采用了事件循环机制:主循环等待某事件发生,一旦事件发生,就依次处理这些发生的事件(如判断事件类型,进行 I/O 请求等)。
一个进程虽然任一时刻只能处理一个请求,但是处理每个请求的事件时,耗时控制在 1 毫秒以内,这样 1 秒内就可以处理上千个请求,把时间拉长来看,多个请求复用了一个进程,这就是多路复用。
以下介绍 select/poll/epoll 内核提供给用户态的多路复用系统调用,进程可以通过一个系统调用函数从内核中获取多个事件。
4.3.2 插叙:文件描述符
如果忘记文件描述符是个啥,可以看我之前写的操作系统文件系统调用API,在调用 open 系统调用时的整数返回值就是文件描述符。
文件描述符只是一个整数,是每个进程私有的,在 UNIX 系统中用于访问文件。因此,一旦文件被打开,你可以使用文件描述符来读取或写入文件,假定你有权这样做。
每一个进程都有一个数据结构 task_struct,该结构体里有一个指向「文件描述符数组」的成员指针。该数组里列出这个进程打开的所有文件的文件描述符。
默认情况下每个进程都有 3 个打开的文件描述符,用于标准输入、输出和错误。这些描述符让程序轻松读取来自终端的输入以及打印输出到屏幕。
刚才说 Socket 是一个文件,所以每个 Socket 在进程内也有它的文件描述符。
import socket
# 创建套接字
server_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
print(server_socket)
print(server_socket.fileno()) # 注意这是个方法
# 输出结果 可以看到文件描述符 fd=3
<socket.socket fd=3, family=AddressFamily.AF_INET, type=SocketKind.SOCK_STREAM, proto=0, laddr=('0.0.0.0', 0)>
34.3.3 select
select()检查 I/O 描述符集合。
C 语言中,它们的地址通过 readfds、writefds 和 errorfds 传入,分别查看它们中的某些描述符是否已准备好读取,是否准备好写入,或有异常情况待处理。
Python 中,文件描述符是通过三个list传入的,含义同上。返回值是三个列表,对应已经 select 的准备好的文件描述符。
# 用户态创建套接字
server_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
# print(server_socket)
server_socket.bind(('0.0.0.0', 8080))
server_socket.listen(5)
# 监控套接字 事件循环机制 系统调用
readable, writable, exceptional = select.select([server_socket], [], [])
# 返回值 readable 有一个元素,就是 server_socket 其 fd = 3
print(readable[0].fileno())
# 用户态遍历文件描述符集合
for s in readable:
if s.fileno() is server_socket.fileno():
client_socket, addr = server_socket.accept()
print(f"Connection from {addr}")select 实现多路复用的方式是,将已连接的 Socket 都放到一个文件描述符集合,然后调用 select 函数将文件描述符集合拷贝到内核里,让内核来检查是否有网络事件产生。检查的方式很粗暴,就是通过遍历文件描述符集合的方式,当检查到有事件产生后,将此 Socket 标记为可读或可写, 接着再把整个文件描述符集合拷贝回用户态里。
然后用户态还需要再通过遍历的方法找到可读或可写的 Socket,然后再对其处理。
所以,对于 select 这种方式,需要进行 2 次「遍历」文件描述符集合,一次是在内核态里,一个次是在用户态里 ,而且还会发生 2 次「拷贝」文件描述符集合,先从用户空间传入内核空间,由内核修改后,再传出到用户空间中。
关于 poll:
select 使用固定长度的 BitsMap,表示文件描述符集合,而且所支持的文件描述符的个数是有限制的,在 Linux 系统中,由内核中的 FD_SETSIZE 限制, 默认最大值为 1024,只能监听 0~1023 的文件描述符。
poll 不再用 BitsMap 来存储所关注的文件描述符,取而代之用动态数组,以链表形式来组织,突破了 select 的文件描述符个数限制,当然还会受到系统文件描述符限制。
但是 poll 和 select 并没有太大的本质区别,都是使用「线性结构」存储进程关注的 Socket 集合,因此都需要遍历文件描述符集合来找到可读或可写的 Socket,时间复杂度为 O(n),而且也需要在用户态与内核态之间拷贝文件描述符集合,这种方式随着并发数上来,性能的损耗会呈指数级增长。
4.3.4 epoll
epoll 通过两个方面,很好解决了 select/poll 的问题。
第一点,epoll 在内核里使用红黑树来跟踪进程所有待检测的文件描述字,把需要监控的 socket 通过 epoll_ctl() 函数加入内核中的红黑树里,红黑树是个高效的数据结构,增删改一般时间复杂度是 O(logn)。而 select/poll 内核里没有类似 epoll 红黑树这种保存所有待检测的 socket 的数据结构,所以 select/poll 每次操作时都传入整个 socket 集合给内核,而 epoll 因为在内核维护了红黑树,可以保存所有待检测的 socket ,所以只需要传入一个待检测的 socket,减少了内核和用户空间大量的数据拷贝和内存分配。
第二点, epoll 使用事件驱动的机制,内核里维护了一个链表来记录就绪事件,当某个 socket 有事件发生时,通过回调函数内核会将其加入到这个就绪事件列表中,当用户调用 epoll_wait() 函数时,只会返回有事件发生的文件描述符的个数,不需要像 select/poll 那样轮询扫描整个 socket 集合,大大提高了检测的效率。
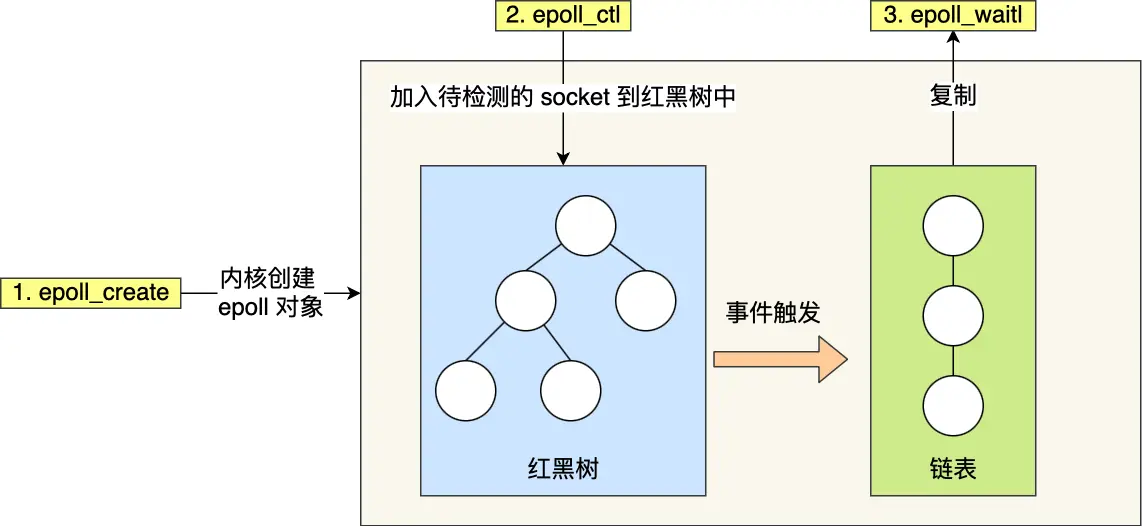
epoll 的方式即使监听的 Socket 数量越多的时候,效率不会大幅度降低,能够同时监听的 Socket 的数目也非常的多了,上限就为系统定义的进程打开的最大文件描述符个数。因而,epoll 被称为解决 C10K 问题的利器。
#include <sys/socket.h>
#include <netinet/in.h>
#include <arpa/inet.h>
#include <unistd.h>
#include <fcntl.h>
#include <sys/epoll.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#define MAX_EVENTS 10
int main()
{
int s = socket(AF_INET, SOCK_STREAM, 0);
// 专用于 IPv4 的 SocketAddr 结构体
struct sockaddr_in server_addr;
memset(&server_addr, 0, sizeof(server_addr));
server_addr.sin_family = AF_INET;
// IPv4 127.0.0.1
server_addr.sin_addr.s_addr = 0x7f000001;
server_addr.sin_port = htons(8080);
bind(s, &server_addr, sizeof(server_addr));
listen(s, SOMAXCONN);
int epfd = epoll_create1(0);
struct epoll_event ev;
ev.events = EPOLLIN;
ev.data.fd = s;
// 将所有需要监听的socket添加到epfd中
epoll_ctl(epfd, EPOLL_CTL_ADD, s, &ev);
// 事件发生的缓冲区
struct epoll_event events[MAX_EVENTS];
while (1)
{
int n = epoll_wait(epfd, events, MAX_EVENTS, -1);
for (int i = 0; i < n; i++)
{
if (events[i].data.fd == s)
{
// 是服务端socket,有新连接
struct sockaddr_in client_addr;
socklen_t client_len = sizeof(client_addr);
int client_fd = accept(s, &client_addr, &client_len);
// fcntl 是一个用于控制文件描述符/文件状态等的系统调用
// F_GETFL 获取文件状态标志 如 O_RDONLY、O_WRONLY、O_NONBLOCK 等
int flags = fcntl(client_fd, F_GETFL, 0);
// F_SETFL 设置文件状态标志。
fcntl(client_fd, F_SETFL, flags | O_NONBLOCK);
ev.events = EPOLLIN | EPOLLET; // 边缘触发模式
ev.data.fd = client_fd;
epoll_ctl(epfd, EPOLL_CTL_ADD, client_fd, &ev)
}
else
{
// 是客户端socket,处理客户端数据
int client_fd = events[i].data.fd;
char buffer[1024];
ssize_t count = read(client_fd, buffer, sizeof(buffer));
// 处理接收到的数据
buffer[count] = '\0';
printf("Received: %s\n", buffer);
// 回显数据
write(client_fd, buffer, count);
}
}
}
}4.3.5 边缘触发与水平触发
epoll 支持两种事件触发模式,分别是边缘触发(edge-triggered,ET)和水平触发(level-triggered,LT)。
这两个术语还挺抽象的,其实它们的区别还是很好理解的。
使用边缘触发模式时,当被监控的 Socket 描述符上有可读事件发生时,服务器端只会从 epoll_wait 中苏醒一次,即使进程没有调用 read 函数从内核读取数据,也依然只苏醒一次,因此我们程序要保证一次性将内核缓冲区的数据读取完;
使用水平触发模式时,当被监控的 Socket 上有可读事件发生时,服务器端不断地从 epoll_wait 中苏醒,直到内核缓冲区数据被 read 函数读完才结束,目的是告诉我们有数据需要读取;
如果使用水平触发模式,当内核通知文件描述符可读写时,接下来还可以继续去检测它的状态,看它是否依然可读或可写。所以在收到通知后,没必要一次执行尽可能多的读写操作。
如果使用边缘触发模式,I/O 事件发生时只会通知一次,而且我们不知道到底能读写多少数据,所以在收到通知后应尽可能地读写数据,以免错失读写的机会。因此,我们会循环从文件描述符读写数据,那么如果文件描述符是阻塞的,没有数据可读写时,进程会阻塞在读写函数那里,程序就没办法继续往下执行。所以,边缘触发模式一般和非阻塞 I/O 搭配使用,程序会一直执行 I/O 操作,直到系统调用(如 read 和 write)返回错误,错误类型为 EAGAIN 或 EWOULDBLOCK。
一般来说,边缘触发的效率比水平触发的效率要高,因为边缘触发可以减少 epoll_wait 的系统调用次数,系统调用也是有一定的开销的的,毕竟也存在上下文的切换。
另外,使用 I/O 多路复用时,最好搭配非阻塞 I/O 一起使用;就是多路复用 API 返回的事件并不一定可读写的,如果使用阻塞 I/O, 那么在调用 read/write 时则会发生程序阻塞,因此最好搭配非阻塞 I/O,以便应对极少数的特殊情况。
4.4 Reactor 与 Proactor
I/O 多路复用接口写网络程序,是面向过程的方式写代码的,这样的开发的效率不高。
于是,大佬们基于面向对象的思想,对 I/O 多路复用作了一层封装,让使用者不用考虑底层网络 API 的细节,只需要关注应用代码的编写。
大佬们还为这种模式取了个让人第一时间难以理解的名字:Reactor 模式。
来了一个事件,Reactor 就有相对应的反应/响应。
事实上,Reactor 模式也叫 Dispatcher 模式,我觉得这个名字更贴合该模式的含义,即 I/O 多路复用监听事件,收到事件后,根据事件类型分配(Dispatch)给某个进程 / 线程。
Reactor 模式主要由 Reactor 和处理资源池这两个核心部分组成,它俩负责的事情如下:
Reactor 负责监听和分发事件,事件类型包含连接事件、读写事件;
处理资源池负责处理事件,如 read -> 业务逻辑 -> send;
Reactor 模式是灵活多变的,可以应对不同的业务场景,灵活在于:
Reactor 的数量可以只有一个,也可以有多个;
处理资源池可以是单个进程 / 线程,也可以是多个进程 /线程;
4.4.1 单 Reactor 单进程 / 单进程
我们把上面的代码做一个简单的封装:
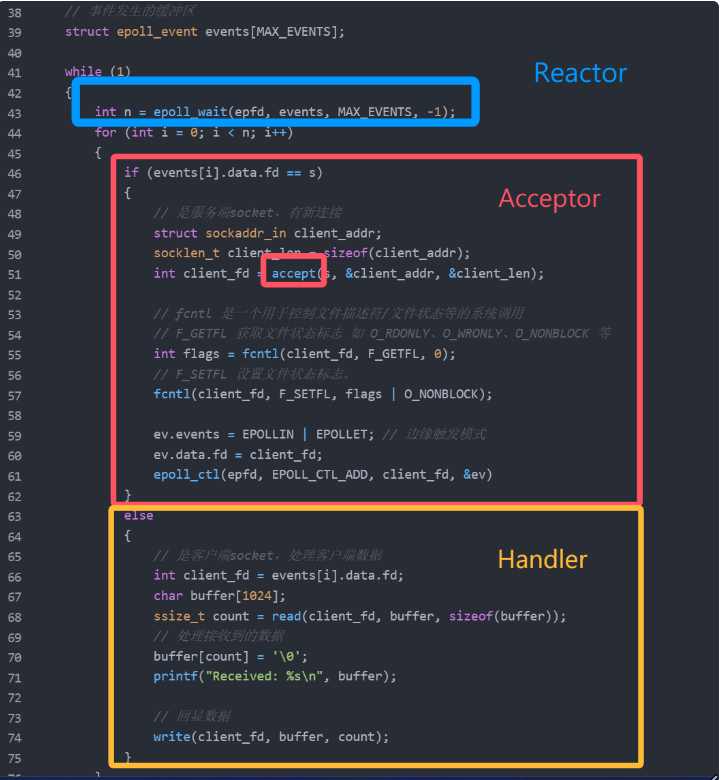
示意图如下:
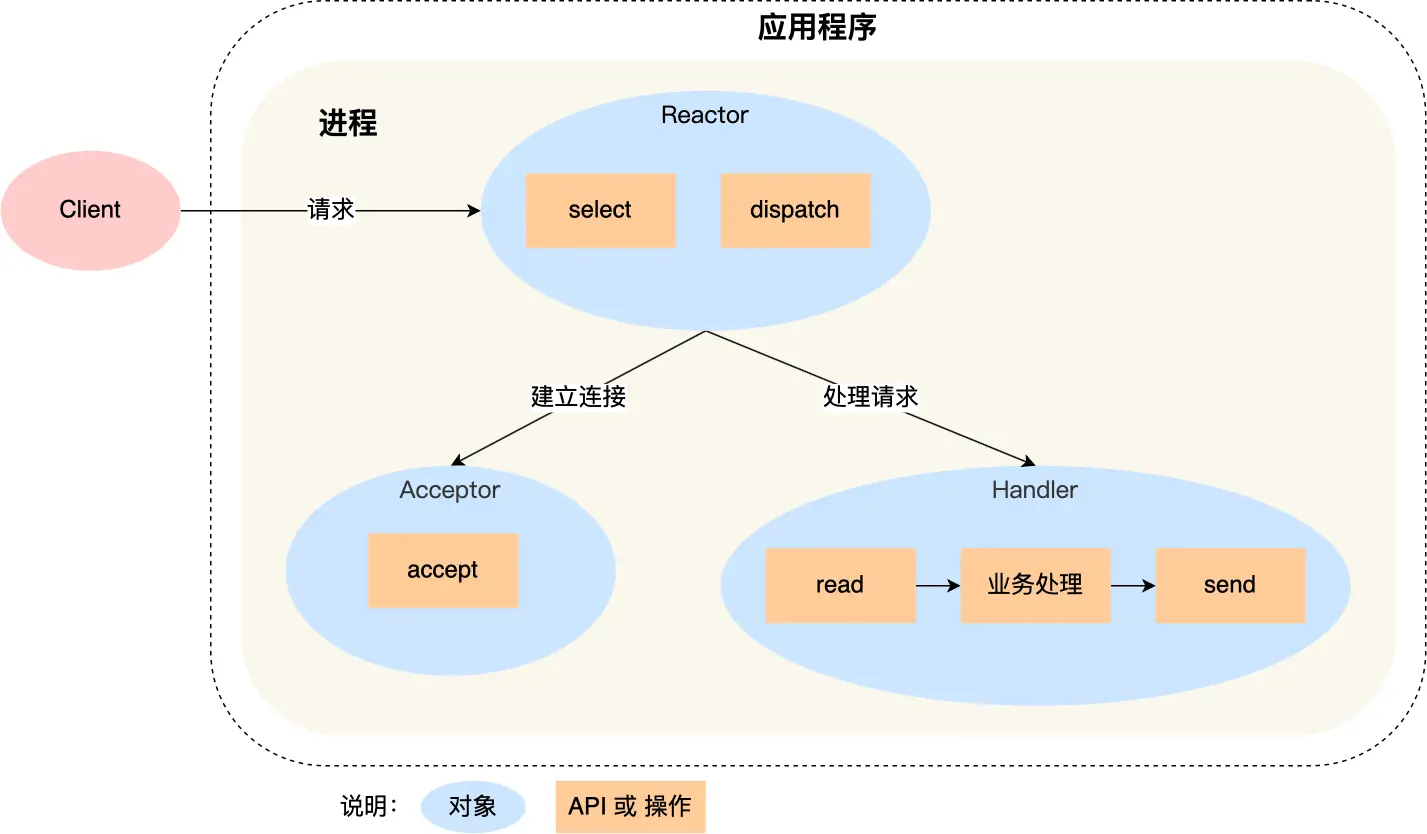
Reactor 对象通过 select (IO 多路复用接口) 监听事件,收到事件后通过 dispatch 进行分发,具体分发给 Acceptor 对象还是 Handler 对象,还要看收到的事件类型;
如果是连接建立的事件,则交由 Acceptor 对象进行处理,Acceptor 对象会通过 accept 方法 获取连接,并创建一个 Handler 对象来处理后续的响应事件;
如果不是连接建立事件, 则交由当前连接对应的 Handler 对象来进行响应;
Handler 对象通过 read -> 业务处理 -> send 的流程来完成完整的业务流程。
Redis 是由 C 语言实现的,在 Redis 6.0 版本之前采用的正是「单 Reactor 单进程」的方案,因为 Redis 业务处理主要是在内存中完成,操作的速度是很快的,性能瓶颈不在 CPU 上,所以 Redis 对于命令的处理是单进程的方案。
4.4.2 单 Reactor 多线程
单线程存在 2 个缺点:
第一个缺点,因为只有一个进程,无法充分利用 多核 CPU 的性能;
第二个缺点,Handler 对象在业务处理时,整个进程是无法处理其他连接的事件的,如果业务处理耗时比较长,那么就造成响应的延迟;
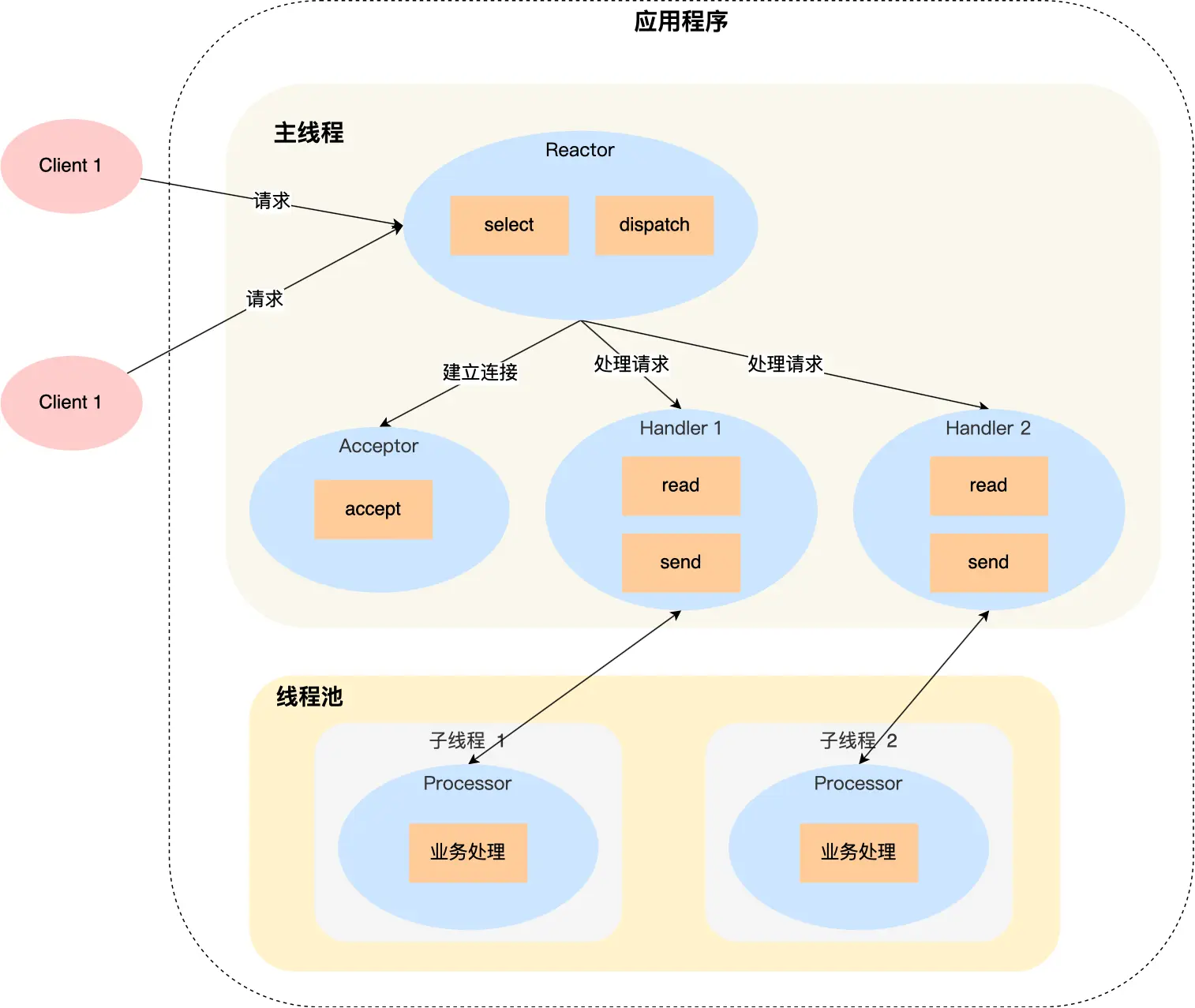
Handler 对象不再负责业务处理,只负责数据的接收和发送,Handler 对象通过 read 读取到数据后,会将数据发给子线程里的 Processor 对象进行业务处理;
子线程里的 Processor 对象就进行业务处理,处理完后,将结果发给主线程中的 Handler 对象,接着由 Handler 通过 send 方法将响应结果发送给 client;
可能涉及共享数据的竞争,需要在共享资源上加上互斥锁。
4.4.3 多 Reactor 多进程 / 多线程
单 Reactor」的模式还有个问题,因为一个 Reactor 对象承担所有事件的监听和响应,而且只在主线程中运行,在面对瞬间高并发的场景时,容易成为性能的瓶颈的地方。
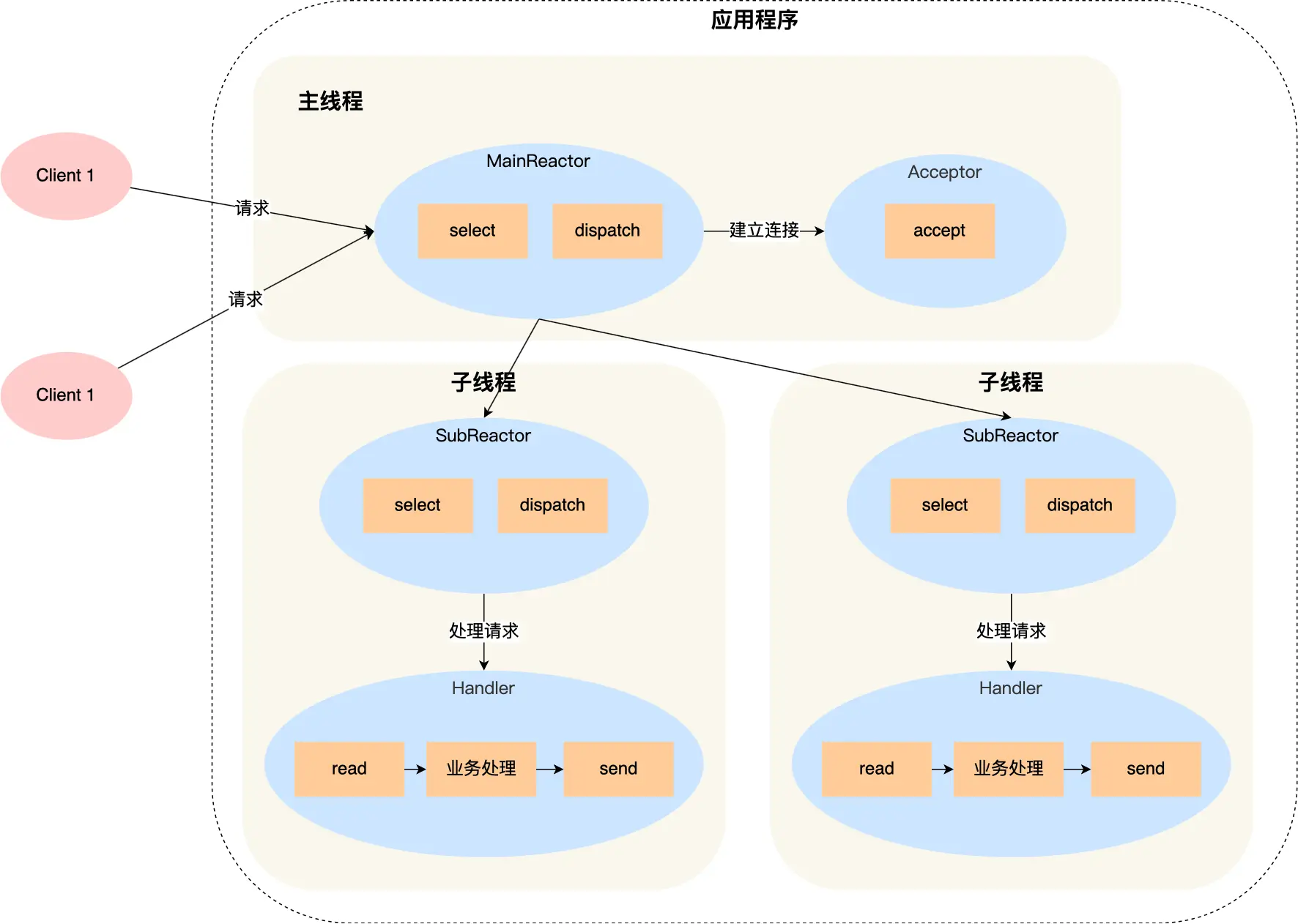
主线程中的 MainReactor 对象通过 select 监控连接建立事件,收到事件后通过 Acceptor 对象中的 accept 获取连接,将新的连接分配给某个子线程;
子线程中的 SubReactor 对象将 MainReactor 对象分配的连接加入 select 继续进行监听,并创建一个 Handler 用于处理连接的响应事件。
如果有新的事件发生时,SubReactor 对象会调用当前连接对应的 Handler 对象来进行响应。
Handler 对象通过 read -> 业务处理 -> send 的流程来完成完整的业务流程。
大名鼎鼎的两个开源软件 Netty 和 Memcache 都采用了「多 Reactor 多线程」的方案。
采用了「多 Reactor 多进程」方案的开源软件是 Nginx,不过方案与标准的多 Reactor 多进程有些差异。具体差异表现在主进程中仅仅用来初始化 socket,并没有创建 mainReactor 来 accept 连接,而是由子进程的 Reactor 来 accept 连接,通过锁来控制一次只有一个子进程进行 accept(防止出现惊群现象),子进程 accept 新连接后就放到自己的 Reactor 进行处理,不会再分配给其他子进程。
5. Java Web:从 Socket 到 Spring Boot
待续……
参考
小林Coding
https://zhuanlan.zhihu.com/p/657915089
https://zhuanlan.zhihu.com/p/133375078
https://ruanyifeng.com/blog/2014/09/illustration-ssl.html
计算机网络(原书第7版): 自顶向下方法
https://www.cnblogs.com/wongbingming/p/13212306.html
华栋 计算机系统